- -# -**`AdvancedHMC.build_tree`** — *Method*. - - - -Recursivly build a tree for a given depth `j`. - - -source
- -# -**`AdvancedHMC.check_left_subtree`** — *Method*. - - - -```julia -check_left_subtree( - h::Hamiltonian, t::T, tleft::T, tright::T -) where {T<:BinaryTree{<:StrictGeneralisedNoUTurn}} -``` - -Do a U-turn check between the leftmost phase point of `t` and the leftmost phase point of `tright`, the right subtree. - - -source
- -# -**`AdvancedHMC.check_right_subtree`** — *Method*. - - - -```julia -check_left_subtree( - h::Hamiltonian, t::T, tleft::T, tright::T -) where {T<:BinaryTree{<:StrictGeneralisedNoUTurn}} -``` - -Do a U-turn check between the rightmost phase point of `t` and the rightmost phase point of `tleft`, the left subtree. - - -source
- -# -**`AdvancedHMC.combine`** — *Method*. - - - -```julia -combine(treeleft::BinaryTree, treeright::BinaryTree) -``` - -Merge a left tree `treeleft` and a right tree `treeright` under given Hamiltonian `h`, then draw a new candidate sample and update related statistics for the resulting tree. - - -source
- -# -**`AdvancedHMC.find_good_stepsize`** — *Method*. - - - -Find a good initial leap-frog step-size via heuristic search. - - -source
- -# -**`AdvancedHMC.isterminated`** — *Method*. - - - -```julia -isterminated(h::Hamiltonian, t::BinaryTree{<:ClassicNoUTurn}) -``` - -Detect U turn for two phase points (`zleft` and `zright`) under given Hamiltonian `h` using the (original) no-U-turn cirterion. - -Ref: https://arxiv.org/abs/1111.4246, https://arxiv.org/abs/1701.02434 - - -source
- -# -**`AdvancedHMC.isterminated`** — *Method*. - - - -```julia -isterminated(h::Hamiltonian, t::BinaryTree{<:GeneralisedNoUTurn}) -``` - -Detect U turn for two phase points (`zleft` and `zright`) under given Hamiltonian `h` using the generalised no-U-turn criterion. - -Ref: https://arxiv.org/abs/1701.02434 - - -source
- -# -**`AdvancedHMC.isterminated`** — *Method*. - - - -```julia -isterminated( - h::Hamiltonian, t::T, tleft::T, tright::T -) where {T<:BinaryTree{<:StrictGeneralisedNoUTurn}} -``` - -Detect U turn for two phase points (`zleft` and `zright`) under given Hamiltonian `h` using the generalised no-U-turn criterion with additional U-turn checks. - -Ref: https://arxiv.org/abs/1701.02434 https://github.com/stan-dev/stan/pull/2800 - - -source
- -# -**`AdvancedHMC.maxabs`** — *Method*. - - - -```julia -maxabs(a, b) -``` - -Return the value with the largest absolute value. - - -source
- -# -**`AdvancedHMC.mh_accept_ratio`** — *Method*. - - - -Perform MH acceptance based on energy, i.e. negative log probability. - - -source
- -# -**`AdvancedHMC.nom_step_size`** — *Method*. - - - -```julia -nom_step_size(::AbstractIntegrator) -``` - -Get the nominal integration step size. The current integration step size may differ from this, for example if the step size is jittered. Nominal step size is usually used in adaptation. - - -source
- -# -**`AdvancedHMC.pm_next!`** — *Method*. - - - -Progress meter update with all trajectory stats, iteration number and metric shown. - - -source
- -# -**`AdvancedHMC.randcat`** — *Method*. - - - -```julia -randcat(rng, P::AbstractMatrix) -``` - -Generating Categorical random variables in a vectorized mode. `P` is supposed to be a matrix of (D, N) where each column is a probability vector. - -Example - -``` -P = [ - 0.5 0.3; - 0.4 0.6; - 0.1 0.1 -] -u = [0.3, 0.4] -C = [ - 0.5 0.3 - 0.9 0.9 - 1.0 1.0 -] -``` - -Then `C .< u'` is - -``` -[ - 0 1 - 0 0 - 0 0 -] -``` - -thus `convert.(Int, vec(sum(C .< u'; dims=1))) .+ 1` equals `[1, 2]`. - - -source
- -# -**`AdvancedHMC.simple_pm_next!`** — *Method*. - - - -Simple progress meter update without any show values. - - -source
- -# -**`AdvancedHMC.stat`** — *Method*. - - - -Returns the statistics for transition `t`. - - -source
- -# -**`AdvancedHMC.step_size`** — *Function*. - - - -```julia -step_size(::AbstractIntegrator) -``` - -Get the current integration step size. - - -source
- -# -**`AdvancedHMC.temper`** — *Method*. - - - -```julia -temper(lf::TemperedLeapfrog, r, step::NamedTuple{(:i, :is_half),<:Tuple{Integer,Bool}}, n_steps::Int) -``` - -Tempering step. `step` is a named tuple with - - * `i` being the current leapfrog iteration and - * `is_half` indicating whether or not it's (the first) half momentum/tempering step - - -source
- -# -**`AdvancedHMC.transition`** — *Method*. - - - -```julia -transition(τ::AbstractTrajectory{I}, h::Hamiltonian, z::PhasePoint) -``` - -Make a MCMC transition from phase point `z` using the trajectory `τ` under Hamiltonian `h`. - -NOTE: This is a RNG-implicit fallback function for `transition(GLOBAL_RNG, τ, h, z)` - - -source
- -# -**`StatsBase.sample`** — *Method*. - - - -```julia -sample( - rng::AbstractRNG, - h::Hamiltonian, - τ::AbstractProposal, - θ::AbstractVecOrMat{T}, - n_samples::Int, - adaptor::AbstractAdaptor=NoAdaptation(), - n_adapts::Int=min(div(n_samples, 10), 1_000); - drop_warmup::Bool=false, - verbose::Bool=true, - progress::Bool=false -) -``` - -Sample `n_samples` samples using the proposal `τ` under Hamiltonian `h`. - - * The randomness is controlled by `rng`. - - * If `rng` is not provided, `GLOBAL_RNG` will be used. - * The initial point is given by `θ`. - * The adaptor is set by `adaptor`, for which the default is no adaptation. - - * It will perform `n_adapts` steps of adaptation, for which the default is the minimum of `1_000` and 10% of `n_samples` - * `drop_warmup` controls to drop the samples during adaptation phase or not - * `verbose` controls the verbosity - * `progress` controls whether to show the progress meter or not - - -source
- - - - - - -## Types - -# -**`AdvancedHMC.AbstractIntegrator`** — *Type*. - - - -```julia -abstract type AbstractIntegrator -``` - -Represents an integrator used to simulate the Hamiltonian system. - -**Implementation** - -A `AbstractIntegrator` is expected to have the following implementations: - - * `stat`(@ref) - * `nom_step_size`(@ref) - * `step_size`(@ref) - - -source
- -# -**`AdvancedHMC.AbstractProposal`** — *Type*. - - - -Abstract Markov chain Monte Carlo proposal. - - -source
- -# -**`AdvancedHMC.AbstractTrajectory`** — *Type*. - - - -Hamiltonian dynamics numerical simulation trajectories. - - -source
- -# -**`AdvancedHMC.AbstractTrajectorySampler`** — *Type*. - - - -Defines how to sample a phase-point from the simulated trajectory. - - -source
- -# -**`AdvancedHMC.BinaryTree`** — *Type*. - - - -A full binary tree trajectory with only necessary leaves and information stored. - - -source
- -# -**`AdvancedHMC.ClassicNoUTurn`** — *Type*. - - - -```julia -struct ClassicNoUTurn <: AdvancedHMC.AbstractTerminationCriterion -``` - -Classic No-U-Turn criterion as described in Eq. (9) in [1]. - -Informally, this will terminate the trajectory expansion if continuing the simulation either forwards or backwards in time will decrease the distance between the left-most and right-most positions. - -**References** - -1. Hoffman, M. D., & Gelman, A. (2014). The No-U-Turn Sampler: adaptively setting path lengths in Hamiltonian Monte Carlo. Journal of Machine Learning Research, 15(1), 1593-1623. ([arXiv](http://arxiv.org/abs/1111.4246)) - - -source
- -# -**`AdvancedHMC.EndPointTS`** — *Type*. - - - -```julia -struct EndPointTS <: AdvancedHMC.AbstractTrajectorySampler -``` - -Samples the end-point of the trajectory. - - -source
- -# -**`AdvancedHMC.GeneralisedNoUTurn`** — *Type*. - - - -```julia -struct GeneralisedNoUTurn{T<:(AbstractArray{var"#s58",1} where var"#s58"<:Real)} <: AdvancedHMC.AbstractTerminationCriterion -``` - -Generalised No-U-Turn criterion as described in Section A.4.2 in [1]. - -**Fields** - - * `rho::AbstractArray{var"#s58",1} where var"#s58"<:Real` - - Integral or sum of momenta along the integration path. - -**References** - -1. Betancourt, M. (2017). A Conceptual Introduction to Hamiltonian Monte Carlo. [arXiv preprint arXiv:1701.02434](https://arxiv.org/abs/1701.02434). - - -source
- -# -**`AdvancedHMC.HMCDA`** — *Type*. - - - -```julia -struct HMCDA{S<:AdvancedHMC.AbstractTrajectorySampler, I<:AdvancedHMC.AbstractIntegrator} <: AdvancedHMC.DynamicTrajectory{I<:AdvancedHMC.AbstractIntegrator} -``` - -Standard HMC implementation with fixed total trajectory length. - -**Fields** - - * `integrator::AdvancedHMC.AbstractIntegrator` - - Integrator used to simulate trajectory. - * `λ::AbstractFloat` - - Total length of the trajectory, i.e. take `floor(λ / integrator_step)` number of leapfrog steps. - -**References** - -1. Neal, R. M. (2011). MCMC using Hamiltonian dynamics. Handbook of Markov chain Monte Carlo, 2(11), 2. ([arXiv](https://arxiv.org/pdf/1206.1901)) - - -source
- -# -**`AdvancedHMC.JitteredLeapfrog`** — *Type*. - - - -```julia -struct JitteredLeapfrog{FT<:AbstractFloat, T<:Union{AbstractArray{FT<:AbstractFloat,1}, FT<:AbstractFloat}} <: AdvancedHMC.AbstractLeapfrog{T<:Union{AbstractArray{FT<:AbstractFloat,1}, FT<:AbstractFloat}} -``` - -Leapfrog integrator with randomly "jittered" step size `ϵ` for every trajectory. - -**Fields** - - * `ϵ0::Union{AbstractArray{FT,1}, FT} where FT<:AbstractFloat` - - Nominal (non-jittered) step size. - * `jitter::AbstractFloat` - - The proportion of the nominal step size `ϵ0` that may be added or subtracted. - * `ϵ::Union{AbstractArray{FT,1}, FT} where FT<:AbstractFloat` - - Current (jittered) step size. - -**Description** - -This is the same as `LeapFrog`(@ref) but with a "jittered" step size. This means that at the beginning of each trajectory we sample a step size `ϵ` by adding or subtracting from the nominal/base step size `ϵ0` some random proportion of `ϵ0`, with the proportion specified by `jitter`, i.e. `ϵ = ϵ0 - jitter * ϵ0 * rand()`. p Jittering might help alleviate issues related to poor interactions with a fixed step size: - - * In regions with high "curvature" the current choice of step size might mean over-shoot leading to almost all steps being rejected. Randomly sampling the step size at the beginning of the trajectories can therefore increase the probability of escaping such high-curvature regions. - * Exact periodicity of the simulated trajectories might occur, i.e. you might be so unlucky as to simulate the trajectory forwards in time `L ϵ` and ending up at the same point (which results in non-ergodicity; see Section 3.2 in [1]). If momentum is refreshed before each trajectory, then this should not happen *exactly* but it can still be an issue in practice. Randomly choosing the step-size `ϵ` might help alleviate such problems. - -**References** - -1. Neal, R. M. (2011). MCMC using Hamiltonian dynamics. Handbook of Markov chain Monte Carlo, 2(11), 2. ([arXiv](https://arxiv.org/pdf/1206.1901)) - - -source
- -# -**`AdvancedHMC.Leapfrog`** — *Type*. - - - -```julia -struct Leapfrog{T<:(Union{AbstractArray{var"#s58",1}, var"#s58"} where var"#s58"<:AbstractFloat)} <: AdvancedHMC.AbstractLeapfrog{T<:(Union{AbstractArray{var"#s58",1}, var"#s58"} where var"#s58"<:AbstractFloat)} -``` - -Leapfrog integrator with fixed step size `ϵ`. - -**Fields** - - * `ϵ::Union{AbstractArray{var"#s58",1}, var"#s58"} where var"#s58"<:AbstractFloat` - - Step size. - - -source
- -# -**`AdvancedHMC.MultinomialTS`** — *Type*. - - - -```julia -struct MultinomialTS{F<:AbstractFloat} <: AdvancedHMC.AbstractTrajectorySampler -``` - -Multinomial trajectory sampler carried during the building of the tree. It contains the weight of the tree, defined as the total probabilities of the leaves. - -**Fields** - - * `zcand::AdvancedHMC.PhasePoint` - - Sampled candidate `PhasePoint`. - * `ℓw::AbstractFloat` - - Total energy for the given tree, i.e. the sum of energies of all leaves. - - -source
- -# -**`AdvancedHMC.MultinomialTS`** — *Method*. - - - -```julia -MultinomialTS(s::MultinomialTS, H0::AbstractFloat, zcand::PhasePoint) -``` - -Multinomial sampler for a trajectory consisting only a leaf node. - - * tree weight is the (unnormalised) energy of the leaf. - - -source
- -# -**`AdvancedHMC.MultinomialTS`** — *Method*. - - - -```julia -MultinomialTS(rng::AbstractRNG, z0::PhasePoint) -``` - -Multinomial sampler for the starting single leaf tree. (Log) weights for leaf nodes are their (unnormalised) Hamiltonian energies. - -Ref: https://github.com/stan-dev/stan/blob/develop/src/stan/mcmc/hmc/nuts/base_nuts.hpp#L226 - - -source
- -# -**`AdvancedHMC.NUTS`** — *Type*. - - - -Dynamic trajectory HMC using the no-U-turn termination criteria algorithm. - - -source
- -# -**`AdvancedHMC.NUTS`** — *Method*. - - - -```julia -NUTS(args...) = NUTS{MultinomialTS,GeneralisedNoUTurn}(args...) -``` - -Create an instance for the No-U-Turn sampling algorithm with multinomial sampling and original no U-turn criterion. - -Below is the doc for NUTS{S,C}. - -``` -NUTS{S,C}( - integrator::I, - max_depth::Int=10, - Δ_max::F=1000.0 -) where {I<:AbstractIntegrator,F<:AbstractFloat,S<:AbstractTrajectorySampler,C<:AbstractTerminationCriterion} -``` - -Create an instance for the No-U-Turn sampling algorithm. - - -source
- -# -**`AdvancedHMC.NUTS`** — *Method*. - - - -```julia -NUTS{S,C}( - integrator::I, - max_depth::Int=10, - Δ_max::F=1000.0 -) where {I<:AbstractIntegrator,F<:AbstractFloat,S<:AbstractTrajectorySampler,C<:AbstractTerminationCriterion} -``` - -Create an instance for the No-U-Turn sampling algorithm. - - -source
- -# -**`AdvancedHMC.SliceTS`** — *Type*. - - - -```julia -struct SliceTS{F<:AbstractFloat} <: AdvancedHMC.AbstractTrajectorySampler -``` - -Trajectory slice sampler carried during the building of the tree. It contains the slice variable and the number of acceptable condidates in the tree. - -**Fields** - - * `zcand::AdvancedHMC.PhasePoint` - - Sampled candidate `PhasePoint`. - * `ℓu::AbstractFloat` - - Slice variable in log-space. - * `n::Int64` - - Number of acceptable candidates, i.e. those with probability larger than slice variable `u`. - - -source
- -# -**`AdvancedHMC.SliceTS`** — *Method*. - - - -```julia -SliceTS(rng::AbstractRNG, z0::PhasePoint) -``` - -Slice sampler for the starting single leaf tree. Slice variable is initialized. - - -source
- -# -**`AdvancedHMC.SliceTS`** — *Method*. - - - -```julia -SliceTS(s::SliceTS, H0::AbstractFloat, zcand::PhasePoint) -``` - -Create a slice sampler for a single leaf tree: - - * the slice variable is copied from the passed-in sampler `s` and - * the number of acceptable candicates is computed by comparing the slice variable against the current energy. - - -source
- -# -**`AdvancedHMC.StaticTrajectory`** — *Type*. - - - -```julia -struct StaticTrajectory{S<:AdvancedHMC.AbstractTrajectorySampler, I<:AdvancedHMC.AbstractIntegrator} <: AdvancedHMC.AbstractTrajectory{I<:AdvancedHMC.AbstractIntegrator} -``` - -Static HMC with a fixed number of leapfrog steps. - -**Fields** - - * `integrator::AdvancedHMC.AbstractIntegrator` - - Integrator used to simulate trajectory. - * `n_steps::Int64` - - Number of steps to simulate, i.e. length of trajectory will be `n_steps + 1`. - -**References** - -1. Neal, R. M. (2011). MCMC using Hamiltonian dynamics. Handbook of Markov chain Monte Carlo, 2(11), 2. ([arXiv](https://arxiv.org/pdf/1206.1901)) - - -source
- -# -**`AdvancedHMC.StrictGeneralisedNoUTurn`** — *Type*. - - - -```julia -struct StrictGeneralisedNoUTurn{T<:(AbstractArray{var"#s58",1} where var"#s58"<:Real)} <: AdvancedHMC.AbstractTerminationCriterion -``` - -Generalised No-U-Turn criterion as described in Section A.4.2 in [1] with added U-turn check as described in [2]. - -**Fields** - - * `rho::AbstractArray{var"#s58",1} where var"#s58"<:Real` - - Integral or sum of momenta along the integration path. - -**References** - -1. Betancourt, M. (2017). A Conceptual Introduction to Hamiltonian Monte Carlo. [arXiv preprint arXiv:1701.02434](https://arxiv.org/abs/1701.02434). -2. [https://github.com/stan-dev/stan/pull/2800](https://github.com/stan-dev/stan/pull/2800) - - -source
- -# -**`AdvancedHMC.TemperedLeapfrog`** — *Type*. - - - -```julia -struct TemperedLeapfrog{FT<:AbstractFloat, T<:Union{AbstractArray{FT<:AbstractFloat,1}, FT<:AbstractFloat}} <: AdvancedHMC.AbstractLeapfrog{T<:Union{AbstractArray{FT<:AbstractFloat,1}, FT<:AbstractFloat}} -``` - -Tempered leapfrog integrator with fixed step size `ϵ` and "temperature" `α`. - -**Fields** - - * `ϵ::Union{AbstractArray{FT,1}, FT} where FT<:AbstractFloat` - - Step size. - * `α::AbstractFloat` - - Temperature parameter. - -**Description** - -Tempering can potentially allow greater exploration of the posterior, e.g. in a multi-modal posterior jumps between the modes can be more likely to occur. - - -source
- -# -**`AdvancedHMC.Termination`** — *Type*. - - - -```julia -Termination -``` - -Termination reasons - - * `dynamic`: due to stoping criteria - * `numerical`: due to large energy deviation from starting (possibly numerical errors) - - -source
- -# -**`AdvancedHMC.Termination`** — *Method*. - - - -```julia -Termination(s::MultinomialTS, nt::NUTS, H0::F, H′::F) where {F<:AbstractFloat} -``` - -Check termination of a Hamiltonian trajectory. - - -source
- -# -**`AdvancedHMC.Termination`** — *Method*. - - - -```julia -Termination(s::SliceTS, nt::NUTS, H0::F, H′::F) where {F<:AbstractFloat} -``` - -Check termination of a Hamiltonian trajectory. - - -source
- -# -**`AdvancedHMC.Transition`** — *Type*. - - - -```julia -struct Transition{P<:AdvancedHMC.PhasePoint, NT<:NamedTuple} -``` - -A transition that contains the phase point and other statistics of the transition. - -**Fields** - - * `z::AdvancedHMC.PhasePoint` - - Phase-point for the transition. - * `stat::NamedTuple` - - Statistics related to the transition, e.g. energy. - - -source
- diff --git a/_docs/library/api.md b/_docs/library/api.md deleted file mode 100644 index 5d4b2b9cc..000000000 --- a/_docs/library/api.md +++ /dev/null @@ -1,521 +0,0 @@ ---- -title: API -permalink: /docs/library/ -toc: true ---- - - - - - - - -## Index - -- [`Turing.BinomialLogit`]({{site.baseurl}}/docs/library/#Turing.BinomialLogit) -- [`Turing.Flat`]({{site.baseurl}}/docs/library/#Turing.Flat) -- [`Turing.FlatPos`]({{site.baseurl}}/docs/library/#Turing.FlatPos) -- [`Turing.OrderedLogistic`]({{site.baseurl}}/docs/library/#Turing.OrderedLogistic) -- [`Turing.Inference.Gibbs`]({{site.baseurl}}/docs/library/#Turing.Inference.Gibbs) -- [`Turing.Inference.HMC`]({{site.baseurl}}/docs/library/#Turing.Inference.HMC) -- [`Turing.Inference.HMCDA`]({{site.baseurl}}/docs/library/#Turing.Inference.HMCDA) -- [`Turing.Inference.IS`]({{site.baseurl}}/docs/library/#Turing.Inference.IS) -- [`Turing.Inference.MH`]({{site.baseurl}}/docs/library/#Turing.Inference.MH) -- [`Turing.Inference.NUTS`]({{site.baseurl}}/docs/library/#Turing.Inference.NUTS) -- [`Turing.Inference.PG`]({{site.baseurl}}/docs/library/#Turing.Inference.PG) -- [`Turing.Inference.SMC`]({{site.baseurl}}/docs/library/#Turing.Inference.SMC) -- [`Libtask.TArray`]({{site.baseurl}}/docs/library/#Libtask.TArray) -- [`Libtask.tzeros`]({{site.baseurl}}/docs/library/#Libtask.tzeros) - - - - - - -## Modelling - -### # **`DynamicPPL.@model`** — *Macro*. - - -```julia -@model(expr[, warn = true]) -``` - -Macro to specify a probabilistic model. - -If `warn` is `true`, a warning is displayed if internal variable names are used in the model definition. - -**Examples** - -Model definition: - -```julia -@model function model(x, y = 42) - ... -end -``` - -To generate a `Model`, call `model(xvalue)` or `model(xvalue, yvalue)`. - - - - - - -## Samplers - -### # **`DynamicPPL.Sampler`** — *Type*. - - -```julia -Sampler{T} -``` - -Generic interface for implementing inference algorithms. An implementation of an algorithm should include the following: - -1. A type specifying the algorithm and its parameters, derived from InferenceAlgorithm -2. A method of `sample` function that produces results of inference, which is where actual inference happens. - -DynamicPPL translates models to chunks that call the modelling functions at specified points. The dispatch is based on the value of a `sampler` variable. To include a new inference algorithm implements the requirements mentioned above in a separate file, then include that file at the end of this one. - -### # **`Turing.Inference.Gibbs`** — *Type*. - - -```julia -Gibbs(algs...) -``` - -Compositional MCMC interface. Gibbs sampling combines one or more sampling algorithms, each of which samples from a different set of variables in a model. - -Example: - -```julia -@model gibbs_example(x) = begin - v1 ~ Normal(0,1) - v2 ~ Categorical(5) -end -``` - -**Use PG for a 'v2' variable, and use HMC for the 'v1' variable.** - -**Note that v2 is discrete, so the PG sampler is more appropriate** - -**than is HMC.** - -alg = Gibbs(HMC(0.2, 3, :v1), PG(20, :v2)) ``` - -Tips: - - * `HMC` and `NUTS` are fast samplers, and can throw off particle-based - -methods like Particle Gibbs. You can increase the effectiveness of particle sampling by including more particles in the particle sampler. - - -source
- -### # **`Turing.Inference.HMC`** — *Type*. - - -```julia -HMC(ϵ::Float64, n_leapfrog::Int) -``` - -Hamiltonian Monte Carlo sampler with static trajectory. - -Arguments: - - * `ϵ::Float64` : The leapfrog step size to use. - * `n_leapfrog::Int` : The number of leapfrop steps to use. - -Usage: - -```julia -HMC(0.05, 10) -``` - -Tips: - - * If you are receiving gradient errors when using `HMC`, try reducing the leapfrog step size `ϵ`, e.g. - -```julia -# Original step size -sample(gdemo([1.5, 2]), HMC(0.1, 10), 1000) - -# Reduced step size -sample(gdemo([1.5, 2]), HMC(0.01, 10), 1000) -``` - - -source
- -### # **`Turing.Inference.HMCDA`** — *Type*. - - -```julia -HMCDA(n_adapts::Int, δ::Float64, λ::Float64; ϵ::Float64=0.0) -``` - -Hamiltonian Monte Carlo sampler with Dual Averaging algorithm. - -Usage: - -```julia -HMCDA(200, 0.65, 0.3) -``` - -Arguments: - - * `n_adapts::Int` : Numbers of samples to use for adaptation. - * `δ::Float64` : Target acceptance rate. 65% is often recommended. - * `λ::Float64` : Target leapfrop length. - * `ϵ::Float64=0.0` : Inital step size; 0 means automatically search by Turing. - -For more information, please view the following paper ([arXiv link](https://arxiv.org/abs/1111.4246)): - - * Hoffman, Matthew D., and Andrew Gelman. "The No-U-turn sampler: adaptively setting path lengths in Hamiltonian Monte Carlo." Journal of Machine Learning Research 15, no. 1 (2014): 1593-1623. - - -source
- -### # **`Turing.Inference.IS`** — *Type*. - - -```julia -IS() -``` - -Importance sampling algorithm. - -Note that this method is particle-based, and arrays of variables must be stored in a [`TArray`]({{site.baseurl}}/docs/library/#Libtask.TArray) object. - -Usage: - -```julia -IS() -``` - -Example: - -```julia -# Define a simple Normal model with unknown mean and variance. -@model gdemo(x) = begin - s ~ InverseGamma(2,3) - m ~ Normal(0,sqrt.(s)) - x[1] ~ Normal(m, sqrt.(s)) - x[2] ~ Normal(m, sqrt.(s)) - return s, m -end - -sample(gdemo([1.5, 2]), IS(), 1000) -``` - - -source
- -### # **`Turing.Inference.MH`** — *Type*. - - -```julia -MH(space...) -``` - -Construct a Metropolis-Hastings algorithm. - -The arguments `space` can be - - * Blank (i.e. `MH()`), in which case `MH` defaults to using the prior for each parameter as the proposal distribution. - * A set of one or more symbols to sample with `MH` in conjunction with `Gibbs`, i.e. `Gibbs(MH(:m), PG(10, :s))` - * An iterable of pairs or tuples mapping a `Symbol` to a `AdvancedMH.Proposal`, `Distribution`, or `Function` that generates returns a conditional proposal distribution. - * A covariance matrix to use as for mean-zero multivariate normal proposals. - -**Examples** - -The default `MH` will use propose samples from the prior distribution using `AdvancedMH.StaticProposal`. - -```julia -@model function gdemo(x, y) - s ~ InverseGamma(2,3) - m ~ Normal(0, sqrt(s)) - x ~ Normal(m, sqrt(s)) - y ~ Normal(m, sqrt(s)) -end - -chain = sample(gdemo(1.5, 2.0), MH(), 1_000) -mean(chain) -``` - -Alternatively, you can specify particular parameters to sample if you want to combine sampling from multiple samplers: - -`````julia -@model function gdemo(x, y) - s ~ InverseGamma(2,3) - m ~ Normal(0, sqrt(s)) - x ~ Normal(m, sqrt(s)) - y ~ Normal(m, sqrt(s)) -end - -# Samples s with MH and m with PG -chain = sample(gdemo(1.5, 2.0), Gibbs(MH(:s), PG(10, :m)), 1_000) -mean(chain) -```` - -Using custom distributions defaults to using static MH: - -````` - -julia @model function gdemo(x, y) s ~ InverseGamma(2,3) m ~ Normal(0, sqrt(s)) x ~ Normal(m, sqrt(s)) y ~ Normal(m, sqrt(s)) end - -**Use a static proposal for s and random walk with proposal** - -**standard deviation of 0.25 for m.** - -chain = sample( gdemo(1.5, 2.0), MH( :s => InverseGamma(2, 3), :m => Normal(0, 1) ), 1_000 ) mean(chain) - -```` - -Specifying explicit proposals using the `AdvancedMH` interface: - -```julia -@model function gdemo(x, y) - s ~ InverseGamma(2,3) - m ~ Normal(0, sqrt(s)) - x ~ Normal(m, sqrt(s)) - y ~ Normal(m, sqrt(s)) -end - -# Use a static proposal for s and random walk with proposal -# standard deviation of 0.25 for m. -chain = sample( - gdemo(1.5, 2.0), - MH( - :s => AdvancedMH.StaticProposal(InverseGamma(2,3)), - :m => AdvancedMH.RandomWalkProposal(Normal(0, 0.25)) - ), - 1_000 -) -mean(chain) -```` - -Using a custom function to specify a conditional distribution: - -`````julia -@model function gdemo(x, y) - s ~ InverseGamma(2,3) - m ~ Normal(0, sqrt(s)) - x ~ Normal(m, sqrt(s)) - y ~ Normal(m, sqrt(s)) -end - -# Use a static proposal for s and and a conditional proposal for m, -# where the proposal is centered around the current sample. -chain = sample( - gdemo(1.5, 2.0), - MH( - :s => InverseGamma(2, 3), - :m => x -> Normal(x, 1) - ), - 1_000 -) -mean(chain) -```` - -Providing a covariance matrix will cause `MH` to perform random-walk -sampling in the transformed space with proposals drawn from a multivariate -normal distribution. The provided matrix must be positive semi-definite and square. Usage: - -````` - -julia @model function gdemo(x, y) s ~ InverseGamma(2,3) m ~ Normal(0, sqrt(s)) x ~ Normal(m, sqrt(s)) y ~ Normal(m, sqrt(s)) end - -**Providing a custom variance-covariance matrix** - -chain = sample( gdemo(1.5, 2.0), MH( [0.25 0.05; 0.05 0.50] ), 1_000 ) mean(chain) ```` - - -source
- -### # **`Turing.Inference.NUTS`** — *Type*. - - -```julia -NUTS(n_adapts::Int, δ::Float64; max_depth::Int=5, Δ_max::Float64=1000.0, ϵ::Float64=0.0) -``` - -No-U-Turn Sampler (NUTS) sampler. - -Usage: - -```julia -NUTS() # Use default NUTS configuration. -NUTS(1000, 0.65) # Use 1000 adaption steps, and target accept ratio 0.65. -``` - -Arguments: - - * `n_adapts::Int` : The number of samples to use with adaptation. - * `δ::Float64` : Target acceptance rate for dual averaging. - * `max_depth::Int` : Maximum doubling tree depth. - * `Δ_max::Float64` : Maximum divergence during doubling tree. - * `ϵ::Float64` : Inital step size; 0 means automatically searching using a heuristic procedure. - - -source
- -### # **`Turing.Inference.PG`** — *Type*. - - -```julia -struct PG{space, R} <: Turing.Inference.ParticleInference -``` - -Particle Gibbs sampler. - -Note that this method is particle-based, and arrays of variables must be stored in a [`TArray`]({{site.baseurl}}/docs/library/#Libtask.TArray) object. - -**Fields** - - * `nparticles::Int64` - - Number of particles. - * `resampler::Any` - - Resampling algorithm. - - -source
- -### # **`Turing.Inference.SMC`** — *Type*. - - -```julia -struct SMC{space, R} <: Turing.Inference.ParticleInference -``` - -Sequential Monte Carlo sampler. - -**Fields** - - * `resampler::Any` - - -source
- - - - - - -## Distributions - -### # **`Turing.Flat`** — *Type*. - - -```julia -Flat <: ContinuousUnivariateDistribution -``` - -A distribution with support and density of one everywhere. - - -source
- -### # **`Turing.FlatPos`** — *Type*. - - -```julia -FlatPos(l::Real) -``` - -A distribution with a lower bound of `l` and a density of one at every `x` above `l`. - - -source
- -### # **`Turing.BinomialLogit`** — *Type*. - - -```julia -BinomialLogit(n<:Real, I<:Integer) -``` - -A univariate binomial logit distribution. - - -source
- - -!!! warning "Missing docstring." - Missing docstring for `VecBinomialLogit`. Check Documenter's build log for details. - - -### # **`Turing.OrderedLogistic`** — *Type*. - - -```julia -OrderedLogistic(η::Any, cutpoints<:AbstractVector) -``` - -An ordered logistic distribution. - - -source
- - - - - - -## Data Structures - -### # **`Libtask.TArray`** — *Type*. - - -```julia -TArray{T}(dims, ...) -``` - -Implementation of data structures that automatically perform copy-on-write after task copying. - -If current*task is an existing key in `s`, then return `s[current*task]`. Otherwise, return`s[current*task] = s[last*task]`. - -Usage: - -```julia -TArray(dim) -``` - -Example: - -```julia -ta = TArray(4) # init -for i in 1:4 ta[i] = i end # assign -Array(ta) # convert to 4-element Array{Int64,1}: [1, 2, 3, 4] -``` - - - - - - -## Utilities - -### # **`Libtask.tzeros`** — *Function*. - - -```julia - tzeros(dims, ...) -``` - -Construct a distributed array of zeros. Trailing arguments are the same as those accepted by `TArray`. - -```julia -tzeros(dim) -``` - -Example: - -```julia -tz = tzeros(4) # construct -Array(tz) # convert to 4-element Array{Int64,1}: [0, 0, 0, 0] -``` - diff --git a/_docs/library/bijectors.md b/_docs/library/bijectors.md deleted file mode 100644 index 0a2c0245f..000000000 --- a/_docs/library/bijectors.md +++ /dev/null @@ -1,612 +0,0 @@ ---- -title: Bijectors -permalink: /docs/library/bijectors/ -toc: true ---- - - - - - -## Index - -- [`Bijectors.ADBijector`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.ADBijector) -- [`Bijectors.AbstractBijector`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.AbstractBijector) -- [`Bijectors.Bijector`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.Bijector) -- [`Bijectors.Composed`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.Composed) -- [`Bijectors.CorrBijector`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.CorrBijector) -- [`Bijectors.Inverse`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.Inverse) -- [`Bijectors.Permute`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.Permute) -- [`Bijectors.Stacked`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.Stacked) -- [`Bijectors._link_chol_lkj`]({{site.baseurl}}/docs/library/bijectors/#Bijectors._link_chol_lkj-Tuple{Any}) -- [`Bijectors.bijector`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.bijector-Tuple{Distribution{Univariate,Discrete}}) -- [`Bijectors.composel`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.composel-Union{Tuple{Vararg{Bijector{N},N1} where N1}, Tuple{N}} where N) -- [`Bijectors.composer`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.composer-Union{Tuple{Vararg{Bijector{N},N1} where N1}, Tuple{N}} where N) -- [`Bijectors.compute_r`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.compute_r-Tuple{AbstractArray{var"#s107",1} where var"#s107"<:Real,Any,Any}) -- [`Bijectors.find_alpha`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.find_alpha-Tuple{AbstractArray{var"#s107",1} where var"#s107"<:Real,Any,Any,Any}) -- [`Bijectors.forward`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.forward-Tuple{Distribution}) -- [`Bijectors.forward`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.forward-Tuple{Bijector,Any}) -- [`Bijectors.isclosedform`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.isclosedform-Tuple{Bijector}) -- [`Bijectors.logabsdetjac`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.logabsdetjac-Tuple{Inverse{var"#s23",N} where N where var"#s23"<:Bijector,Any}) -- [`Bijectors.logabsdetjac`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.logabsdetjac-Tuple{ADBijector,Real}) -- [`Bijectors.logabsdetjacinv`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.logabsdetjacinv-Tuple{Bijector,Any}) -- [`Bijectors.logabsdetjacinv`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.logabsdetjacinv-Tuple{Bijectors.TransformedDistribution{var"#s108",var"#s107",Univariate} where var"#s107"<:Bijector where var"#s108"<:Distribution,Real}) -- [`Bijectors.logpdf_with_jac`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.logpdf_with_jac-Tuple{Bijectors.TransformedDistribution{var"#s108",var"#s107",Univariate} where var"#s107"<:Bijector where var"#s108"<:Distribution,Real}) -- [`Bijectors.transformed`]({{site.baseurl}}/docs/library/bijectors/#Bijectors.transformed-Tuple{Distribution,Bijector}) - - - - - - -## Functions - -# -**`Bijectors._link_chol_lkj`** — *Method*. - - - -```julia -function _link_chol_lkj(w) -``` - -Link function for cholesky factor. - -An alternative and maybe more efficient implementation was considered: - -``` -for i=2:K, j=(i+1):K - z[i, j] = (w[i, j] / w[i-1, j]) * (z[i-1, j] / sqrt(1 - z[i-1, j]^2)) -end -``` - -But this implementation will not work when w[i-1, j] = 0. Though it is a zero measure set, unit matrix initialization will not work. - -For equivelence, following explanations is given by @torfjelde: - -For `(i, j)` in the loop below, we define - -``` -z₍ᵢ₋₁, ⱼ₎ = w₍ᵢ₋₁,ⱼ₎ * ∏ₖ₌₁ⁱ⁻² (1 / √(1 - z₍ₖ,ⱼ₎²)) -``` - -and so - -``` -z₍ᵢ,ⱼ₎ = w₍ᵢ,ⱼ₎ * ∏ₖ₌₁ⁱ⁻¹ (1 / √(1 - z₍ₖ,ⱼ₎²)) - = (w₍ᵢ,ⱼ₎ * / √(1 - z₍ᵢ₋₁,ⱼ₎²)) * (∏ₖ₌₁ⁱ⁻² 1 / √(1 - z₍ₖ,ⱼ₎²)) - = (w₍ᵢ,ⱼ₎ * / √(1 - z₍ᵢ₋₁,ⱼ₎²)) * (w₍ᵢ₋₁,ⱼ₎ * ∏ₖ₌₁ⁱ⁻² 1 / √(1 - z₍ₖ,ⱼ₎²)) / w₍ᵢ₋₁,ⱼ₎ - = (w₍ᵢ,ⱼ₎ * / √(1 - z₍ᵢ₋₁,ⱼ₎²)) * (z₍ᵢ₋₁,ⱼ₎ / w₍ᵢ₋₁,ⱼ₎) - = (w₍ᵢ,ⱼ₎ / w₍ᵢ₋₁,ⱼ₎) * (z₍ᵢ₋₁,ⱼ₎ / √(1 - z₍ᵢ₋₁,ⱼ₎²)) -``` - -which is the above implementation. - -# -**`Bijectors.bijector`** — *Method*. - - - -```julia -bijector(d::Distribution) -``` - -Returns the constrained-to-unconstrained bijector for distribution `d`. - -# -**`Bijectors.composel`** — *Method*. - - - -```julia -composel(ts::Bijector...)::Composed{<:Tuple} -``` - -Constructs `Composed` such that `ts` are applied left-to-right. - -# -**`Bijectors.composer`** — *Method*. - - - -```julia -composer(ts::Bijector...)::Composed{<:Tuple} -``` - -Constructs `Composed` such that `ts` are applied right-to-left. - -# -**`Bijectors.compute_r`** — *Method*. - - - -```julia -compute_r(y_minus_z0::AbstractVector{<:Real}, α, α_plus_β_hat) -``` - -Compute the unique solution $r$ to the equation - -$$ -\|y_minus_z0\|_2 = r \left(1 + \frac{α_plus_β_hat - α}{α + r}\right) -$$ - -subject to $r ≥ 0$ and $r ≠ α$. - -Since $α > 0$ and $α_plus_β_hat > 0$, the solution is unique and given by - -$$ -r = (\sqrt{(α_plus_β_hat - γ)^2 + 4 α γ} - (α_plus_β_hat - γ)) / 2, -$$ - -where $γ = \|y_minus_z0\|_2$. For details see appendix A.2 of the reference. - -**References** - -D. Rezende, S. Mohamed (2015): Variational Inference with Normalizing Flows. arXiv:1505.05770 - -# -**`Bijectors.find_alpha`** — *Method*. - - - -```julia -find_alpha(y::AbstractVector{<:Real}, wt_y, wt_u_hat, b) -``` - -Compute an (approximate) real-valued solution $α$ to the equation - -$$ -wt_y = α + wt_u_hat tanh(α + b) -$$ - -The uniqueness of the solution is guaranteed since $wt_u_hat ≥ -1$. For details see appendix A.1 of the reference. - -**References** - -D. Rezende, S. Mohamed (2015): Variational Inference with Normalizing Flows. arXiv:1505.05770 - -# -**`Bijectors.forward`** — *Method*. - - - -```julia -forward(b::Bijector, x) -``` - -Computes both `transform` and `logabsdetjac` in one forward pass, and returns a named tuple `(rv=b(x), logabsdetjac=logabsdetjac(b, x))`. - -This defaults to the call above, but often one can re-use computation in the computation of the forward pass and the computation of the `logabsdetjac`. `forward` allows the user to take advantange of such efficiencies, if they exist. - -# -**`Bijectors.forward`** — *Method*. - - - -```julia -forward(d::Distribution) -forward(d::Distribution, num_samples::Int) -``` - -Returns a `NamedTuple` with fields `x`, `y`, `logabsdetjac` and `logpdf`. - -In the case where `d isa TransformedDistribution`, this means - - * `x = rand(d.dist)` - * `y = d.transform(x)` - * `logabsdetjac` is the logabsdetjac of the "forward" transform. - * `logpdf` is the logpdf of `y`, not `x` - -In the case where `d isa Distribution`, this means - - * `x = rand(d)` - * `y = x` - * `logabsdetjac = 0.0` - * `logpdf` is logpdf of `x` - -# -**`Bijectors.isclosedform`** — *Method*. - - - -```julia -isclosedform(b::Bijector)::bool -isclosedform(b⁻¹::Inverse{<:Bijector})::bool -``` - -Returns `true` or `false` depending on whether or not evaluation of `b` has a closed-form implementation. - -Most bijectors have closed-form evaluations, but there are cases where this is not the case. For example the *inverse* evaluation of `PlanarLayer` requires an iterative procedure to evaluate and thus is not differentiable. - -# -**`Bijectors.logabsdetjac`** — *Method*. - - - -Computes the absolute determinant of the Jacobian of the inverse-transformation. - -# -**`Bijectors.logabsdetjac`** — *Method*. - - - -```julia -logabsdetjac(b::Bijector, x) -logabsdetjac(ib::Inverse{<:Bijector}, y) -``` - -Computes the log(abs(det(J(b(x))))) where J is the jacobian of the transform. Similarily for the inverse-transform. - -Default implementation for `Inverse{<:Bijector}` is implemented as `- logabsdetjac` of original `Bijector`. - -# -**`Bijectors.logabsdetjacinv`** — *Method*. - - - -```julia -logabsdetjacinv(b::Bijector, y) -``` - -Just an alias for `logabsdetjac(inv(b), y)`. - -# -**`Bijectors.logabsdetjacinv`** — *Method*. - - - -```julia -logabsdetjacinv(td::UnivariateTransformed, y::Real) -logabsdetjacinv(td::MultivariateTransformed, y::AbstractVector{<:Real}) -``` - -Computes the `logabsdetjac` of the *inverse* transformation, since `rand(td)` returns the *transformed* random variable. - -# -**`Bijectors.logpdf_with_jac`** — *Method*. - - - -```julia -logpdf_with_jac(td::UnivariateTransformed, y::Real) -logpdf_with_jac(td::MvTransformed, y::AbstractVector{<:Real}) -logpdf_with_jac(td::MatrixTransformed, y::AbstractMatrix{<:Real}) -``` - -Makes use of the `forward` method to potentially re-use computation and returns a tuple `(logpdf, logabsdetjac)`. - -# -**`Bijectors.transformed`** — *Method*. - - - -```julia -transformed(d::Distribution) -transformed(d::Distribution, b::Bijector) -``` - -Couples distribution `d` with the bijector `b` by returning a `TransformedDistribution`. - -If no bijector is provided, i.e. `transformed(d)` is called, then `transformed(d, bijector(d))` is returned. - - - - - - -## Types - -# -**`Bijectors.ADBijector`** — *Type*. - - - -Abstract type for a `Bijector{N}` making use of auto-differentation (AD) to implement `jacobian` and, by impliciation, `logabsdetjac`. - -# -**`Bijectors.AbstractBijector`** — *Type*. - - - -Abstract type for a bijector. - -# -**`Bijectors.Bijector`** — *Type*. - - - -Abstract type of bijectors with fixed dimensionality. - -# -**`Bijectors.Composed`** — *Type*. - - - -```julia -Composed(ts::A) - -∘(b1::Bijector{N}, b2::Bijector{N})::Composed{<:Tuple} -composel(ts::Bijector{N}...)::Composed{<:Tuple} -composer(ts::Bijector{N}...)::Composed{<:Tuple} -``` - -where `A` refers to either - - * `Tuple{Vararg{<:Bijector{N}}}`: a tuple of bijectors of dimensionality `N` - * `AbstractArray{<:Bijector{N}}`: an array of bijectors of dimensionality `N` - -A `Bijector` representing composition of bijectors. `composel` and `composer` results in a `Composed` for which application occurs from left-to-right and right-to-left, respectively. - -Note that all the alternative ways of constructing a `Composed` returns a `Tuple` of bijectors. This ensures type-stability of implementations of all relating methdos, e.g. `inv`. - -If you want to use an `Array` as the container instead you can do - -``` -Composed([b1, b2, ...]) -``` - -In general this is not advised since you lose type-stability, but there might be cases where this is desired, e.g. if you have a insanely large number of bijectors to compose. - -**Examples** - -**Simple example** - -Let's consider a simple example of `Exp`: - -```julia-repl -julia> using Bijectors: Exp - -julia> b = Exp() -Exp{0}() - -julia> b ∘ b -Composed{Tuple{Exp{0},Exp{0}},0}((Exp{0}(), Exp{0}())) - -julia> (b ∘ b)(1.0) == exp(exp(1.0)) # evaluation -true - -julia> inv(b ∘ b)(exp(exp(1.0))) == 1.0 # inversion -true - -julia> logabsdetjac(b ∘ b, 1.0) # determinant of jacobian -3.718281828459045 -``` - -**Notes** - -**Order** - -It's important to note that `∘` does what is expected mathematically, which means that the bijectors are applied to the input right-to-left, e.g. first applying `b2` and then `b1`: - -```julia -(b1 ∘ b2)(x) == b1(b2(x)) # => true -``` - -But in the `Composed` struct itself, we store the bijectors left-to-right, so that - -```julia -cb1 = b1 ∘ b2 # => Composed.ts == (b2, b1) -cb2 = composel(b2, b1) # => Composed.ts == (b2, b1) -cb1(x) == cb2(x) == b1(b2(x)) # => true -``` - -**Structure** - -`∘` will result in "flatten" the composition structure while `composel` and `composer` preserve the compositional structure. This is most easily seen by an example: - -```julia-repl -julia> b = Exp() -Exp{0}() - -julia> cb1 = b ∘ b; cb2 = b ∘ b; - -julia> (cb1 ∘ cb2).ts # <= different -(Exp{0}(), Exp{0}(), Exp{0}(), Exp{0}()) - -julia> (cb1 ∘ cb2).ts isa NTuple{4, Exp{0}} -true - -julia> Bijectors.composer(cb1, cb2).ts -(Composed{Tuple{Exp{0},Exp{0}},0}((Exp{0}(), Exp{0}())), Composed{Tuple{Exp{0},Exp{0}},0}((Exp{0}(), Exp{0}()))) - -julia> Bijectors.composer(cb1, cb2).ts isa Tuple{Composed, Composed} -true -``` - -# -**`Bijectors.CorrBijector`** — *Type*. - - - -```julia -CorrBijector <: Bijector{2} -``` - -A bijector implementation of Stan's parametrization method for Correlation matrix: https://mc-stan.org/docs/2_23/reference-manual/correlation-matrix-transform-section.html - -Basically, a unconstrained strictly upper triangular matrix `y` is transformed to a correlation matrix by following readable but not that efficient form: - -``` -K = size(y, 1) -z = tanh.(y) - -for j=1:K, i=1:K - if i>j - w[i,j] = 0 - elseif 1==i==j - w[i,j] = 1 - elseif 1
| Default | Student | Balance | Income | |
|---|---|---|---|---|
| Categorical… | Categorical… | Float64 | Float64 | |
| 1 | No | No | 729.526 | 44361.6 |
| 2 | No | Yes | 817.18 | 12106.1 |
| 3 | No | No | 1073.55 | 31767.1 |
| 4 | No | No | 529.251 | 35704.5 |
| 5 | No | No | 785.656 | 38463.5 |
| 6 | No | Yes | 919.589 | 7491.56 |
| Balance | Income | DefaultNum | StudentNum | |
|---|---|---|---|---|
| Float64 | Float64 | Float64 | Float64 | |
| 1 | 729.526 | 44361.6 | 0.0 | 0.0 |
| 2 | 817.18 | 12106.1 | 0.0 | 1.0 |
| 3 | 1073.55 | 31767.1 | 0.0 | 0.0 |
| 4 | 529.251 | 35704.5 | 0.0 | 0.0 |
| 5 | 785.656 | 38463.5 | 0.0 | 0.0 |
| 6 | 919.589 | 7491.56 | 0.0 | 1.0 |
 -
-The end of this tutorial provides some code that can be used to generate more general network shapes.
-
-
-```julia
-# Turn a vector into a set of weights and biases.
-function unpack(nn_params::AbstractVector)
- W₁ = reshape(nn_params[1:6], 3, 2);
- b₁ = reshape(nn_params[7:9], 3)
-
- W₂ = reshape(nn_params[10:15], 2, 3);
- b₂ = reshape(nn_params[16:17], 2)
-
- Wₒ = reshape(nn_params[18:19], 1, 2);
- bₒ = reshape(nn_params[20:20], 1)
- return W₁, b₁, W₂, b₂, Wₒ, bₒ
-end
-
-# Construct a neural network using Flux and return a predicted value.
-function nn_forward(xs, nn_params::AbstractVector)
- W₁, b₁, W₂, b₂, Wₒ, bₒ = unpack(nn_params)
- nn = Chain(Dense(W₁, b₁, tanh),
- Dense(W₂, b₂, tanh),
- Dense(Wₒ, bₒ, σ))
- return nn(xs)
-end;
-```
-
-The probabalistic model specification below creates a `params` variable, which has 20 normally distributed variables. Each entry in the `params` vector represents weights and biases of our neural net.
-
-
-```julia
-# Create a regularization term and a Gaussain prior variance term.
-alpha = 0.09
-sig = sqrt(1.0 / alpha)
-
-# Specify the probabalistic model.
-@model bayes_nn(xs, ts) = begin
- # Create the weight and bias vector.
- nn_params ~ MvNormal(zeros(20), sig .* ones(20))
-
- # Calculate predictions for the inputs given the weights
- # and biases in theta.
- preds = nn_forward(xs, nn_params)
-
- # Observe each prediction.
- for i = 1:length(ts)
- ts[i] ~ Bernoulli(preds[i])
- end
-end;
-```
-
-Inference can now be performed by calling `sample`. We use the `HMC` sampler here.
-
-
-```julia
-# Perform inference.
-N = 5000
-ch = sample(bayes_nn(hcat(xs...), ts), HMC(0.05, 4), N);
-```
-
-Now we extract the weights and biases from the sampled chain. We'll use these primarily in determining how good a classifier our model is.
-
-
-```julia
-# Extract all weight and bias parameters.
-theta = ch[:nn_params].value.data;
-```
-
-## Prediction Visualization
-
-We can use [MAP estimation](https://en.wikipedia.org/wiki/Maximum_a_posteriori_estimation) to classify our population by using the set of weights that provided the highest log posterior.
-
-
-```julia
-# Plot the data we have.
-plot_data()
-
-# Find the index that provided the highest log posterior in the chain.
-_, i = findmax(ch[:lp].value.data)
-
-# Extract the max row value from i.
-i = i.I[1]
-
-# Plot the posterior distribution with a contour plot.
-x_range = collect(range(-6,stop=6,length=25))
-y_range = collect(range(-6,stop=6,length=25))
-Z = [nn_forward([x, y], theta[i, :])[1] for x=x_range, y=y_range]
-contour!(x_range, y_range, Z)
-```
-
-
-
-
-
-
-
-
-The contour plot above shows that the MAP method is not too bad at classifying our data.
-
-Now we can visualize our predictions.
-
-\$\$
-p(\tilde{x} | X, \alpha) = \int_{\theta} p(\tilde{x} | \theta) p(\theta | X, \alpha) \approx \sum_{\theta \sim p(\theta | X, \alpha)}f_{\theta}(\tilde{x})
-\$\$
-
-The `nn_predict` function takes the average predicted value from a network parameterized by weights drawn from the MCMC chain.
-
-
-```julia
-# Return the average predicted value across
-# multiple weights.
-function nn_predict(x, theta, num)
- mean([nn_forward(x, theta[i,:])[1] for i in 1:10:num])
-end;
-```
-
-Next, we use the `nn_predict` function to predict the value at a sample of points where the `x` and `y` coordinates range between -6 and 6. As we can see below, we still have a satisfactory fit to our data.
-
-
-```julia
-# Plot the average prediction.
-plot_data()
-
-n_end = 1500
-x_range = collect(range(-6,stop=6,length=25))
-y_range = collect(range(-6,stop=6,length=25))
-Z = [nn_predict([x, y], theta, n_end)[1] for x=x_range, y=y_range]
-contour!(x_range, y_range, Z)
-```
-
-
-
-
-
-
-
-
-If you are interested in how the predictive power of our Bayesian neural network evolved between samples, the following graph displays an animation of the contour plot generated from the network weights in samples 1 to 1,000.
-
-
-```julia
-# Number of iterations to plot.
-n_end = 500
-
-anim = @gif for i=1:n_end
- plot_data()
- Z = [nn_forward([x, y], theta[i,:])[1] for x=x_range, y=y_range]
- contour!(x_range, y_range, Z, title="Iteration $$i", clim = (0,1))
-end every 5
-
-
-```
-
- ┌ Info: Saved animation to
- │ fn = /home/cameron/code/TuringTutorials/tmp.gif
- └ @ Plots /home/cameron/.julia/packages/Plots/cc8wh/src/animation.jl:98
-
-
-
-
-
-
-
-The end of this tutorial provides some code that can be used to generate more general network shapes.
-
-
-```julia
-# Turn a vector into a set of weights and biases.
-function unpack(nn_params::AbstractVector)
- W₁ = reshape(nn_params[1:6], 3, 2);
- b₁ = reshape(nn_params[7:9], 3)
-
- W₂ = reshape(nn_params[10:15], 2, 3);
- b₂ = reshape(nn_params[16:17], 2)
-
- Wₒ = reshape(nn_params[18:19], 1, 2);
- bₒ = reshape(nn_params[20:20], 1)
- return W₁, b₁, W₂, b₂, Wₒ, bₒ
-end
-
-# Construct a neural network using Flux and return a predicted value.
-function nn_forward(xs, nn_params::AbstractVector)
- W₁, b₁, W₂, b₂, Wₒ, bₒ = unpack(nn_params)
- nn = Chain(Dense(W₁, b₁, tanh),
- Dense(W₂, b₂, tanh),
- Dense(Wₒ, bₒ, σ))
- return nn(xs)
-end;
-```
-
-The probabalistic model specification below creates a `params` variable, which has 20 normally distributed variables. Each entry in the `params` vector represents weights and biases of our neural net.
-
-
-```julia
-# Create a regularization term and a Gaussain prior variance term.
-alpha = 0.09
-sig = sqrt(1.0 / alpha)
-
-# Specify the probabalistic model.
-@model bayes_nn(xs, ts) = begin
- # Create the weight and bias vector.
- nn_params ~ MvNormal(zeros(20), sig .* ones(20))
-
- # Calculate predictions for the inputs given the weights
- # and biases in theta.
- preds = nn_forward(xs, nn_params)
-
- # Observe each prediction.
- for i = 1:length(ts)
- ts[i] ~ Bernoulli(preds[i])
- end
-end;
-```
-
-Inference can now be performed by calling `sample`. We use the `HMC` sampler here.
-
-
-```julia
-# Perform inference.
-N = 5000
-ch = sample(bayes_nn(hcat(xs...), ts), HMC(0.05, 4), N);
-```
-
-Now we extract the weights and biases from the sampled chain. We'll use these primarily in determining how good a classifier our model is.
-
-
-```julia
-# Extract all weight and bias parameters.
-theta = ch[:nn_params].value.data;
-```
-
-## Prediction Visualization
-
-We can use [MAP estimation](https://en.wikipedia.org/wiki/Maximum_a_posteriori_estimation) to classify our population by using the set of weights that provided the highest log posterior.
-
-
-```julia
-# Plot the data we have.
-plot_data()
-
-# Find the index that provided the highest log posterior in the chain.
-_, i = findmax(ch[:lp].value.data)
-
-# Extract the max row value from i.
-i = i.I[1]
-
-# Plot the posterior distribution with a contour plot.
-x_range = collect(range(-6,stop=6,length=25))
-y_range = collect(range(-6,stop=6,length=25))
-Z = [nn_forward([x, y], theta[i, :])[1] for x=x_range, y=y_range]
-contour!(x_range, y_range, Z)
-```
-
-
-
-
-
-
-
-
-The contour plot above shows that the MAP method is not too bad at classifying our data.
-
-Now we can visualize our predictions.
-
-\$\$
-p(\tilde{x} | X, \alpha) = \int_{\theta} p(\tilde{x} | \theta) p(\theta | X, \alpha) \approx \sum_{\theta \sim p(\theta | X, \alpha)}f_{\theta}(\tilde{x})
-\$\$
-
-The `nn_predict` function takes the average predicted value from a network parameterized by weights drawn from the MCMC chain.
-
-
-```julia
-# Return the average predicted value across
-# multiple weights.
-function nn_predict(x, theta, num)
- mean([nn_forward(x, theta[i,:])[1] for i in 1:10:num])
-end;
-```
-
-Next, we use the `nn_predict` function to predict the value at a sample of points where the `x` and `y` coordinates range between -6 and 6. As we can see below, we still have a satisfactory fit to our data.
-
-
-```julia
-# Plot the average prediction.
-plot_data()
-
-n_end = 1500
-x_range = collect(range(-6,stop=6,length=25))
-y_range = collect(range(-6,stop=6,length=25))
-Z = [nn_predict([x, y], theta, n_end)[1] for x=x_range, y=y_range]
-contour!(x_range, y_range, Z)
-```
-
-
-
-
-
-
-
-
-If you are interested in how the predictive power of our Bayesian neural network evolved between samples, the following graph displays an animation of the contour plot generated from the network weights in samples 1 to 1,000.
-
-
-```julia
-# Number of iterations to plot.
-n_end = 500
-
-anim = @gif for i=1:n_end
- plot_data()
- Z = [nn_forward([x, y], theta[i,:])[1] for x=x_range, y=y_range]
- contour!(x_range, y_range, Z, title="Iteration $$i", clim = (0,1))
-end every 5
-
-
-```
-
- ┌ Info: Saved animation to
- │ fn = /home/cameron/code/TuringTutorials/tmp.gif
- └ @ Plots /home/cameron/.julia/packages/Plots/cc8wh/src/animation.jl:98
-
-
-
-
-
- -
-
-
-## Variational Inference (ADVI)
-
-We can also use Turing's variational inference tools to estimate the parameters of this model. See [variational inference](https://turing.ml/dev/docs/for-developers/variational_inference) for more information.
-
-
-```julia
-using Bijectors
-using Turing: Variational
-
-m = bayes_nn(hcat(xs...), ts);
-
-q = Variational.meanfield(m)
-
-μ = randn(length(q))
-ω = -1 .* ones(length(q))
-
-q = Variational.update(q, μ, exp.(ω));
-
-advi = ADVI(10, 1000)
-q_hat = vi(m, advi, q);
-```
-
- ┌ Info: [ADVI] Should only be seen once: optimizer created for θ
- │ objectid(θ) = 3812708583762184342
- └ @ Turing.Variational /home/cameron/.julia/packages/Turing/cReBm/src/variational/VariationalInference.jl:204
-
-
-
-```julia
-samples = transpose(rand(q_hat, 5000))
-ch_vi = Chains(reshape(samples, size(samples)..., 1), ["nn_params[$$i]" for i = 1:20]);
-
-# Extract all weight and bias parameters.
-theta = ch_vi[:nn_params].value.data;
-```
-
-
-```julia
-# Plot the average prediction.
-plot_data()
-
-n_end = 1500
-x_range = collect(range(-6,stop=6,length=25))
-y_range = collect(range(-6,stop=6,length=25))
-Z = [nn_predict([x, y], theta, n_end)[1] for x=x_range, y=y_range]
-contour!(x_range, y_range, Z)
-```
-
-
-
-
-
-
-
-
-## Generic Bayesian Neural Networks
-
-The below code is intended for use in more general applications, where you need to be able to change the basic network shape fluidly. The code above is highly rigid, and adapting it for other architectures would be time consuming. Currently the code below only supports networks of `Dense` layers.
-
-Here, we solve the same problem as above, but with three additional 2x2 `tanh` hidden layers. You can modify the `network_shape` variable to specify differing architectures. A tuple `(3,2, :tanh)` means you want to construct a `Dense` layer with 3 outputs, 2 inputs, and a `tanh` activation function. You can provide any activation function found in Flux by entering it as a `Symbol` (e.g., the `tanh` function is entered in the third part of the tuple as `:tanh`).
-
-
-```julia
-# Specify the network architecture.
-network_shape = [
- (3,2, :tanh),
- (2,3, :tanh),
- (1,2, :σ)]
-
-# Regularization, parameter variance, and total number of
-# parameters.
-alpha = 0.09
-sig = sqrt(1.0 / alpha)
-num_params = sum([i * o + i for (i, o, _) in network_shape])
-
-# This modification of the unpack function generates a series of vectors
-# given a network shape.
-function unpack(θ::AbstractVector, network_shape::AbstractVector)
- index = 1
- weights = []
- biases = []
- for layer in network_shape
- rows, cols, _ = layer
- size = rows * cols
- last_index_w = size + index - 1
- last_index_b = last_index_w + rows
- push!(weights, reshape(θ[index:last_index_w], rows, cols))
- push!(biases, reshape(θ[last_index_w+1:last_index_b], rows))
- index = last_index_b + 1
- end
- return weights, biases
-end
-
-# Generate an abstract neural network given a shape,
-# and return a prediction.
-function nn_forward(x, θ::AbstractVector, network_shape::AbstractVector)
- weights, biases = unpack(θ, network_shape)
- layers = []
- for i in eachindex(network_shape)
- push!(layers, Dense(weights[i],
- biases[i],
- eval(network_shape[i][3])))
- end
- nn = Chain(layers...)
- return nn(x)
-end
-
-# General Turing specification for a BNN model.
-@model bayes_nn_general(xs, ts, network_shape, num_params) = begin
- θ ~ MvNormal(zeros(num_params), sig .* ones(num_params))
- preds = nn_forward(xs, θ, network_shape)
- for i = 1:length(ts)
- ts[i] ~ Bernoulli(preds[i])
- end
-end
-
-# Set the backend.
-Turing.setadbackend(:reverse_diff)
-
-# Perform inference.
-num_samples = 500
-ch2 = sample(bayes_nn_general(hcat(xs...), ts, network_shape, num_params), NUTS(0.65), num_samples);
-```
-
- ┌ Warning: `Turing.setadbackend(:reverse_diff)` is deprecated. Please use `Turing.setadbackend(:tracker)` to use `Tracker` or `Turing.setadbackend(:reversediff)` to use `ReverseDiff`. To use `ReverseDiff`, please make sure it is loaded separately with `using ReverseDiff`.
- │ caller = setadbackend(::Symbol) at ad.jl:5
- └ @ Turing.Core /home/cameron/.julia/packages/Turing/cReBm/src/core/ad.jl:5
- ┌ Info: Found initial step size
- │ ϵ = 0.2
- └ @ Turing.Inference /home/cameron/.julia/packages/Turing/cReBm/src/inference/hmc.jl:556
-
-
-
-```julia
-# This function makes predictions based on network shape.
-function nn_predict(x, theta, num, network_shape)
- mean([nn_forward(x, theta[i,:], network_shape)[1] for i in 1:10:num])
-end;
-
-# Extract the θ parameters from the sampled chain.
-params2 = ch2[:θ].value.data
-
-plot_data()
-
-x_range = collect(range(-6,stop=6,length=25))
-y_range = collect(range(-6,stop=6,length=25))
-Z = [nn_predict([x, y], params2, length(ch2), network_shape)[1] for x=x_range, y=y_range]
-contour!(x_range, y_range, Z)
-```
-
-
-
-
-
-
-
-
-This has been an introduction to the applications of Turing and Flux in defining Bayesian neural networks.
diff --git a/_tutorials/3_BayesNN_files/3_BayesNN_16_0.svg b/_tutorials/3_BayesNN_files/3_BayesNN_16_0.svg
deleted file mode 100644
index 179549d9e..000000000
--- a/_tutorials/3_BayesNN_files/3_BayesNN_16_0.svg
+++ /dev/null
@@ -1,453 +0,0 @@
-
-
diff --git a/_tutorials/3_BayesNN_files/3_BayesNN_21_0.svg b/_tutorials/3_BayesNN_files/3_BayesNN_21_0.svg
deleted file mode 100644
index c5d7f8b43..000000000
--- a/_tutorials/3_BayesNN_files/3_BayesNN_21_0.svg
+++ /dev/null
@@ -1,458 +0,0 @@
-
-
diff --git a/_tutorials/3_BayesNN_files/3_BayesNN_28_0.svg b/_tutorials/3_BayesNN_files/3_BayesNN_28_0.svg
deleted file mode 100644
index c7af91efb..000000000
--- a/_tutorials/3_BayesNN_files/3_BayesNN_28_0.svg
+++ /dev/null
@@ -1,334 +0,0 @@
-
-
diff --git a/_tutorials/3_BayesNN_files/3_BayesNN_31_0.svg b/_tutorials/3_BayesNN_files/3_BayesNN_31_0.svg
deleted file mode 100644
index 374e9cae0..000000000
--- a/_tutorials/3_BayesNN_files/3_BayesNN_31_0.svg
+++ /dev/null
@@ -1,454 +0,0 @@
-
-
diff --git a/_tutorials/3_BayesNN_files/3_BayesNN_32_0.svg b/_tutorials/3_BayesNN_files/3_BayesNN_32_0.svg
deleted file mode 100644
index 0d58b42aa..000000000
--- a/_tutorials/3_BayesNN_files/3_BayesNN_32_0.svg
+++ /dev/null
@@ -1,538 +0,0 @@
-
-
diff --git a/_tutorials/3_BayesNN_files/3_BayesNN_35_0.svg b/_tutorials/3_BayesNN_files/3_BayesNN_35_0.svg
deleted file mode 100644
index f2118f6ad..000000000
--- a/_tutorials/3_BayesNN_files/3_BayesNN_35_0.svg
+++ /dev/null
@@ -1,553 +0,0 @@
-
-
diff --git a/_tutorials/3_BayesNN_files/3_BayesNN_4_0.svg b/_tutorials/3_BayesNN_files/3_BayesNN_4_0.svg
deleted file mode 100644
index 33e69f84f..000000000
--- a/_tutorials/3_BayesNN_files/3_BayesNN_4_0.svg
+++ /dev/null
@@ -1,214 +0,0 @@
-
-
diff --git a/_tutorials/4_BayesHmm.md b/_tutorials/4_BayesHmm.md
deleted file mode 100644
index 7ffa7cf41..000000000
--- a/_tutorials/4_BayesHmm.md
+++ /dev/null
@@ -1,200 +0,0 @@
----
-title: Bayesian Hidden Markov Models
-permalink: /:collection/:name/
----
-
-# Bayesian Hidden Markov Models
-This tutorial illustrates training Bayesian [Hidden Markov Models](https://en.wikipedia.org/wiki/Hidden_Markov_model) (HMM) using Turing. The main goals are learning the transition matrix, emission parameter, and hidden states. For a more rigorous academic overview on Hidden Markov Models, see [An introduction to Hidden Markov Models and Bayesian Networks](http://mlg.eng.cam.ac.uk/zoubin/papers/ijprai.pdf) (Ghahramani, 2001).
-
-Let's load the libraries we'll need. We also set a random seed (for reproducibility) and the automatic differentiation backend to forward mode (more [here](http://turing.ml/docs/autodiff/) on why this is useful).
-
-
-```julia
-# Load libraries.
-using Turing, Plots, Random
-
-# Turn off progress monitor.
-Turing.turnprogress(false);
-
-# Set a random seed and use the forward_diff AD mode.
-Random.seed!(1234);
-```
-
- ┌ Info: [Turing]: progress logging is disabled globally
- └ @ Turing /home/cameron/.julia/packages/Turing/cReBm/src/Turing.jl:22
-
-
-## Simple State Detection
-
-In this example, we'll use something where the states and emission parameters are straightforward.
-
-
-```julia
-# Define the emission parameter.
-y = [ 1.0, 1.0, 1.0, 1.0, 2.0, 2.0, 2.0, 3.0, 3.0, 3.0, 2.0, 2.0, 2.0, 1.0, 1.0 ];
-N = length(y); K = 3;
-
-# Plot the data we just made.
-plot(y, xlim = (0,15), ylim = (-1,5), size = (500, 250))
-```
-
-
-
-
-
-
-
-
-We can see that we have three states, one for each height of the plot (1, 2, 3). This height is also our emission parameter, so state one produces a value of one, state two produces a value of two, and so on.
-
-Ultimately, we would like to understand three major parameters:
-
-1. The transition matrix. This is a matrix that assigns a probability of switching from one state to any other state, including the state that we are already in.
-2. The emission matrix, which describes a typical value emitted by some state. In the plot above, the emission parameter for state one is simply one.
-3. The state sequence is our understanding of what state we were actually in when we observed some data. This is very important in more sophisticated HMM models, where the emission value does not equal our state.
-
-With this in mind, let's set up our model. We are going to use some of our knowledge as modelers to provide additional information about our system. This takes the form of the prior on our emission parameter.
-
-\$\$
-m_i \sim Normal(i, 0.5), \space m = \{1,2,3\}
-\$\$
-
-Simply put, this says that we expect state one to emit values in a Normally distributed manner, where the mean of each state's emissions is that state's value. The variance of 0.5 helps the model converge more quickly — consider the case where we have a variance of 1 or 2. In this case, the likelihood of observing a 2 when we are in state 1 is actually quite high, as it is within a standard deviation of the true emission value. Applying the prior that we are likely to be tightly centered around the mean prevents our model from being too confused about the state that is generating our observations.
-
-The priors on our transition matrix are noninformative, using `T[i] ~ Dirichlet(ones(K)/K)`. The Dirichlet prior used in this way assumes that the state is likely to change to any other state with equal probability. As we'll see, this transition matrix prior will be overwritten as we observe data.
-
-
-```julia
-# Turing model definition.
-@model BayesHmm(y, K) = begin
- # Get observation length.
- N = length(y)
-
- # State sequence.
- s = tzeros(Int, N)
-
- # Emission matrix.
- m = Vector(undef, K)
-
- # Transition matrix.
- T = Vector{Vector}(undef, K)
-
- # Assign distributions to each element
- # of the transition matrix and the
- # emission matrix.
- for i = 1:K
- T[i] ~ Dirichlet(ones(K)/K)
- m[i] ~ Normal(i, 0.5)
- end
-
- # Observe each point of the input.
- s[1] ~ Categorical(K)
- y[1] ~ Normal(m[s[1]], 0.1)
-
- for i = 2:N
- s[i] ~ Categorical(vec(T[s[i-1]]))
- y[i] ~ Normal(m[s[i]], 0.1)
- end
-end;
-```
-
-We will use a combination of two samplers ([HMC](http://turing.ml/docs/library/#Turing.HMC) and [Particle Gibbs](http://turing.ml/docs/library/#Turing.PG)) by passing them to the [Gibbs](http://turing.ml/docs/library/#Turing.Gibbs) sampler. The Gibbs sampler allows for compositional inference, where we can utilize different samplers on different parameters.
-
-In this case, we use HMC for `m` and `T`, representing the emission and transition matrices respectively. We use the Particle Gibbs sampler for `s`, the state sequence. You may wonder why it is that we are not assigning `s` to the HMC sampler, and why it is that we need compositional Gibbs sampling at all.
-
-The parameter `s` is not a continuous variable. It is a vector of **integers**, and thus Hamiltonian methods like HMC and [NUTS](http://turing.ml/docs/library/#-turingnuts--type) won't work correctly. Gibbs allows us to apply the right tools to the best effect. If you are a particularly advanced user interested in higher performance, you may benefit from setting up your Gibbs sampler to use [different automatic differentiation](http://turing.ml/docs/autodiff/#compositional-sampling-with-differing-ad-modes) backends for each parameter space.
-
-Time to run our sampler.
-
-
-```julia
-g = Gibbs(HMC(0.001, 7, :m, :T), PG(20, :s))
-c = sample(BayesHmm(y, 3), g, 100);
-```
-
-Let's see how well our chain performed. Ordinarily, using the `describe` function from [MCMCChain](https://github.com/TuringLang/MCMCChain.jl) would be a good first step, but we have generated a lot of parameters here (`s[1]`, `s[2]`, `m[1]`, and so on). It's a bit easier to show how our model performed graphically.
-
-The code below generates an animation showing the graph of the data above, and the data our model generates in each sample.
-
-
-```julia
-# Import StatsPlots for animating purposes.
-using StatsPlots
-
-# Extract our m and s parameters from the chain.
-m_set = c[:m].value.data
-s_set = c[:s].value.data
-
-# Iterate through the MCMC samples.
-Ns = 1:length(c)
-
-# Make an animation.
-animation = @animate for i in Ns
- m = m_set[i, :];
- s = Int.(s_set[i,:]);
- emissions = collect(skipmissing(m[s]))
-
- p = plot(y, c = :red,
- size = (500, 250),
- xlabel = "Time",
- ylabel = "State",
- legend = :topright, label = "True data",
- xlim = (0,15),
- ylim = (-1,5));
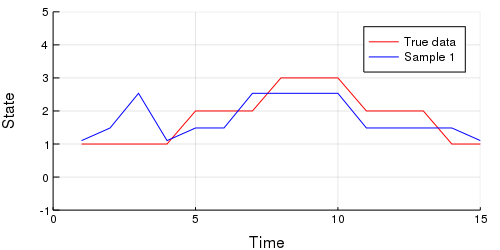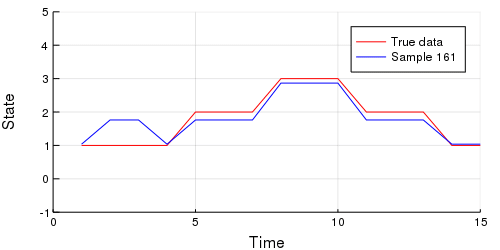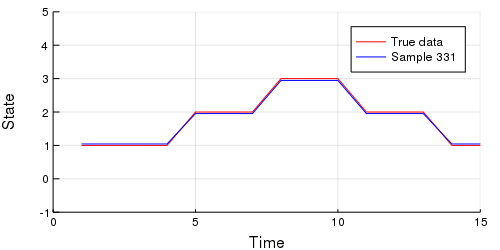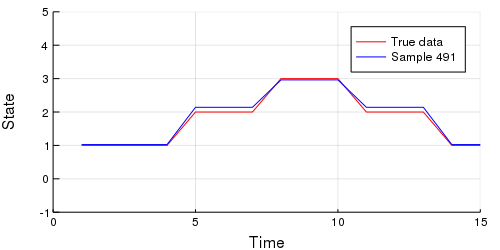
- plot!(emissions, color = :blue, label = "Sample $$N")
-end every 10;
-```
-
-
-
-Looks like our model did a pretty good job, but we should also check to make sure our chain converges. A quick check is to examine whether the diagonal (representing the probability of remaining in the current state) of the transition matrix appears to be stationary. The code below extracts the diagonal and shows a traceplot of each persistence probability.
-
-
-```julia
-# Index the chain with the persistence probabilities.
-subchain = c[:,["T[$$i][$$i]" for i in 1:K],:]
-
-# Plot the chain.
-plot(subchain,
- colordim = :parameter,
- seriestype=:traceplot,
- title = "Persistence Probability",
- legend=:right
- )
-```
-
-
-
-
-
-
-
-
-A cursory examination of the traceplot above indicates that at least `T[3,3]` and possibly `T[2,2]` have converged to something resembling stationary. `T[1,1]`, on the other hand, has a slight "wobble", and seems less consistent than the others. We can use the diagnostic functions provided by [MCMCChain](https://github.com/TuringLang/MCMCChain.jl) to engage in some formal tests, like the Heidelberg and Welch diagnostic:
-
-
-```julia
-heideldiag(c[:T])
-```
-
-
-
-
- 1-element Array{ChainDataFrame{NamedTuple{(:parameters, Symbol("Burn-in"), :Stationarity, Symbol("p-value"), :Mean, :Halfwidth, :Test),Tuple{Array{String,1},Array{Float64,1},Array{Float64,1},Array{Float64,1},Array{Float64,1},Array{Float64,1},Array{Float64,1}}}},1}:
- Heidelberger and Welch Diagnostic - Chain 1
- parameters Burn-in Stationarity p-value Mean Halfwidth Test
- ────────── ─────── ──────────── ─────── ────── ───────── ──────
- T[1][1] 50.0000 0.0000 0.0001 0.5329 0.0063 1.0000
- T[1][2] 50.0000 0.0000 0.0189 0.1291 0.0043 1.0000
- T[1][3] 50.0000 0.0000 0.0230 0.3381 0.0032 1.0000
- T[2][1] 30.0000 1.0000 0.2757 0.0037 0.0000 1.0000
- T[2][2] 0.0000 1.0000 0.1689 0.0707 0.0022 1.0000
- T[2][3] 0.0000 1.0000 0.1365 0.9255 0.0022 1.0000
- T[3][1] 50.0000 0.0000 0.0454 0.4177 0.0147 1.0000
- T[3][2] 40.0000 1.0000 0.0909 0.2549 0.0080 1.0000
- T[3][3] 50.0000 0.0000 0.0098 0.3274 0.0067 1.0000
-
-
-
-
-The p-values on the test suggest that we cannot reject the hypothesis that the observed sequence comes from a stationary distribution, so we can be somewhat more confident that our transition matrix has converged to something reasonable.
diff --git a/_tutorials/4_BayesHmm_files/4_BayesHmm_11_0.svg b/_tutorials/4_BayesHmm_files/4_BayesHmm_11_0.svg
deleted file mode 100644
index a57ff9bc2..000000000
--- a/_tutorials/4_BayesHmm_files/4_BayesHmm_11_0.svg
+++ /dev/null
@@ -1,192 +0,0 @@
-
-
diff --git a/_tutorials/4_BayesHmm_files/4_BayesHmm_3_0.svg b/_tutorials/4_BayesHmm_files/4_BayesHmm_3_0.svg
deleted file mode 100644
index f34e10e66..000000000
--- a/_tutorials/4_BayesHmm_files/4_BayesHmm_3_0.svg
+++ /dev/null
@@ -1,163 +0,0 @@
-
-
diff --git a/_tutorials/5_LinearRegression.md b/_tutorials/5_LinearRegression.md
deleted file mode 100644
index 0f78fe421..000000000
--- a/_tutorials/5_LinearRegression.md
+++ /dev/null
@@ -1,343 +0,0 @@
----
-title: Linear Regression
-permalink: /:collection/:name/
----
-
-# Linear Regression
-
-Turing is powerful when applied to complex hierarchical models, but it can also be put to task at common statistical procedures, like [linear regression](https://en.wikipedia.org/wiki/Linear_regression). This tutorial covers how to implement a linear regression model in Turing.
-
-## Set Up
-
-We begin by importing all the necessary libraries.
-
-
-```julia
-# Import Turing and Distributions.
-using Turing, Distributions
-
-# Import RDatasets.
-using RDatasets
-
-# Import MCMCChains, Plots, and StatPlots for visualizations and diagnostics.
-using MCMCChains, Plots, StatsPlots
-
-# Functionality for splitting and normalizing the data.
-using MLDataUtils: shuffleobs, splitobs, rescale!
-
-# Functionality for evaluating the model predictions.
-using Distances
-
-# Set a seed for reproducibility.
-using Random
-Random.seed!(0)
-
-# Hide the progress prompt while sampling.
-Turing.turnprogress(false);
-```
-
- ┌ Info: Precompiling Turing [fce5fe82-541a-59a6-adf8-730c64b5f9a0]
- └ @ Base loading.jl:1260
- ┌ Info: Precompiling RDatasets [ce6b1742-4840-55fa-b093-852dadbb1d8b]
- └ @ Base loading.jl:1260
- ┌ Info: Precompiling Plots [91a5bcdd-55d7-5caf-9e0b-520d859cae80]
- └ @ Base loading.jl:1260
- ┌ Info: Precompiling StatsPlots [f3b207a7-027a-5e70-b257-86293d7955fd]
- └ @ Base loading.jl:1260
- ┌ Info: Precompiling MLDataUtils [cc2ba9b6-d476-5e6d-8eaf-a92d5412d41d]
- └ @ Base loading.jl:1260
- ┌ Info: [Turing]: progress logging is disabled globally
- └ @ Turing /home/cameron/.julia/packages/Turing/GMBTf/src/Turing.jl:22
-
-
-We will use the `mtcars` dataset from the [RDatasets](https://github.com/johnmyleswhite/RDatasets.jl) package. `mtcars` contains a variety of statistics on different car models, including their miles per gallon, number of cylinders, and horsepower, among others.
-
-We want to know if we can construct a Bayesian linear regression model to predict the miles per gallon of a car, given the other statistics it has. Lets take a look at the data we have.
-
-
-```julia
-# Import the "Default" dataset.
-data = RDatasets.dataset("datasets", "mtcars");
-
-# Show the first six rows of the dataset.
-first(data, 6)
-```
-
-
-
-
-
-
-
-
-## Variational Inference (ADVI)
-
-We can also use Turing's variational inference tools to estimate the parameters of this model. See [variational inference](https://turing.ml/dev/docs/for-developers/variational_inference) for more information.
-
-
-```julia
-using Bijectors
-using Turing: Variational
-
-m = bayes_nn(hcat(xs...), ts);
-
-q = Variational.meanfield(m)
-
-μ = randn(length(q))
-ω = -1 .* ones(length(q))
-
-q = Variational.update(q, μ, exp.(ω));
-
-advi = ADVI(10, 1000)
-q_hat = vi(m, advi, q);
-```
-
- ┌ Info: [ADVI] Should only be seen once: optimizer created for θ
- │ objectid(θ) = 3812708583762184342
- └ @ Turing.Variational /home/cameron/.julia/packages/Turing/cReBm/src/variational/VariationalInference.jl:204
-
-
-
-```julia
-samples = transpose(rand(q_hat, 5000))
-ch_vi = Chains(reshape(samples, size(samples)..., 1), ["nn_params[$$i]" for i = 1:20]);
-
-# Extract all weight and bias parameters.
-theta = ch_vi[:nn_params].value.data;
-```
-
-
-```julia
-# Plot the average prediction.
-plot_data()
-
-n_end = 1500
-x_range = collect(range(-6,stop=6,length=25))
-y_range = collect(range(-6,stop=6,length=25))
-Z = [nn_predict([x, y], theta, n_end)[1] for x=x_range, y=y_range]
-contour!(x_range, y_range, Z)
-```
-
-
-
-
-
-
-
-
-## Generic Bayesian Neural Networks
-
-The below code is intended for use in more general applications, where you need to be able to change the basic network shape fluidly. The code above is highly rigid, and adapting it for other architectures would be time consuming. Currently the code below only supports networks of `Dense` layers.
-
-Here, we solve the same problem as above, but with three additional 2x2 `tanh` hidden layers. You can modify the `network_shape` variable to specify differing architectures. A tuple `(3,2, :tanh)` means you want to construct a `Dense` layer with 3 outputs, 2 inputs, and a `tanh` activation function. You can provide any activation function found in Flux by entering it as a `Symbol` (e.g., the `tanh` function is entered in the third part of the tuple as `:tanh`).
-
-
-```julia
-# Specify the network architecture.
-network_shape = [
- (3,2, :tanh),
- (2,3, :tanh),
- (1,2, :σ)]
-
-# Regularization, parameter variance, and total number of
-# parameters.
-alpha = 0.09
-sig = sqrt(1.0 / alpha)
-num_params = sum([i * o + i for (i, o, _) in network_shape])
-
-# This modification of the unpack function generates a series of vectors
-# given a network shape.
-function unpack(θ::AbstractVector, network_shape::AbstractVector)
- index = 1
- weights = []
- biases = []
- for layer in network_shape
- rows, cols, _ = layer
- size = rows * cols
- last_index_w = size + index - 1
- last_index_b = last_index_w + rows
- push!(weights, reshape(θ[index:last_index_w], rows, cols))
- push!(biases, reshape(θ[last_index_w+1:last_index_b], rows))
- index = last_index_b + 1
- end
- return weights, biases
-end
-
-# Generate an abstract neural network given a shape,
-# and return a prediction.
-function nn_forward(x, θ::AbstractVector, network_shape::AbstractVector)
- weights, biases = unpack(θ, network_shape)
- layers = []
- for i in eachindex(network_shape)
- push!(layers, Dense(weights[i],
- biases[i],
- eval(network_shape[i][3])))
- end
- nn = Chain(layers...)
- return nn(x)
-end
-
-# General Turing specification for a BNN model.
-@model bayes_nn_general(xs, ts, network_shape, num_params) = begin
- θ ~ MvNormal(zeros(num_params), sig .* ones(num_params))
- preds = nn_forward(xs, θ, network_shape)
- for i = 1:length(ts)
- ts[i] ~ Bernoulli(preds[i])
- end
-end
-
-# Set the backend.
-Turing.setadbackend(:reverse_diff)
-
-# Perform inference.
-num_samples = 500
-ch2 = sample(bayes_nn_general(hcat(xs...), ts, network_shape, num_params), NUTS(0.65), num_samples);
-```
-
- ┌ Warning: `Turing.setadbackend(:reverse_diff)` is deprecated. Please use `Turing.setadbackend(:tracker)` to use `Tracker` or `Turing.setadbackend(:reversediff)` to use `ReverseDiff`. To use `ReverseDiff`, please make sure it is loaded separately with `using ReverseDiff`.
- │ caller = setadbackend(::Symbol) at ad.jl:5
- └ @ Turing.Core /home/cameron/.julia/packages/Turing/cReBm/src/core/ad.jl:5
- ┌ Info: Found initial step size
- │ ϵ = 0.2
- └ @ Turing.Inference /home/cameron/.julia/packages/Turing/cReBm/src/inference/hmc.jl:556
-
-
-
-```julia
-# This function makes predictions based on network shape.
-function nn_predict(x, theta, num, network_shape)
- mean([nn_forward(x, theta[i,:], network_shape)[1] for i in 1:10:num])
-end;
-
-# Extract the θ parameters from the sampled chain.
-params2 = ch2[:θ].value.data
-
-plot_data()
-
-x_range = collect(range(-6,stop=6,length=25))
-y_range = collect(range(-6,stop=6,length=25))
-Z = [nn_predict([x, y], params2, length(ch2), network_shape)[1] for x=x_range, y=y_range]
-contour!(x_range, y_range, Z)
-```
-
-
-
-
-
-
-
-
-This has been an introduction to the applications of Turing and Flux in defining Bayesian neural networks.
diff --git a/_tutorials/3_BayesNN_files/3_BayesNN_16_0.svg b/_tutorials/3_BayesNN_files/3_BayesNN_16_0.svg
deleted file mode 100644
index 179549d9e..000000000
--- a/_tutorials/3_BayesNN_files/3_BayesNN_16_0.svg
+++ /dev/null
@@ -1,453 +0,0 @@
-
-
diff --git a/_tutorials/3_BayesNN_files/3_BayesNN_21_0.svg b/_tutorials/3_BayesNN_files/3_BayesNN_21_0.svg
deleted file mode 100644
index c5d7f8b43..000000000
--- a/_tutorials/3_BayesNN_files/3_BayesNN_21_0.svg
+++ /dev/null
@@ -1,458 +0,0 @@
-
-
diff --git a/_tutorials/3_BayesNN_files/3_BayesNN_28_0.svg b/_tutorials/3_BayesNN_files/3_BayesNN_28_0.svg
deleted file mode 100644
index c7af91efb..000000000
--- a/_tutorials/3_BayesNN_files/3_BayesNN_28_0.svg
+++ /dev/null
@@ -1,334 +0,0 @@
-
-
diff --git a/_tutorials/3_BayesNN_files/3_BayesNN_31_0.svg b/_tutorials/3_BayesNN_files/3_BayesNN_31_0.svg
deleted file mode 100644
index 374e9cae0..000000000
--- a/_tutorials/3_BayesNN_files/3_BayesNN_31_0.svg
+++ /dev/null
@@ -1,454 +0,0 @@
-
-
diff --git a/_tutorials/3_BayesNN_files/3_BayesNN_32_0.svg b/_tutorials/3_BayesNN_files/3_BayesNN_32_0.svg
deleted file mode 100644
index 0d58b42aa..000000000
--- a/_tutorials/3_BayesNN_files/3_BayesNN_32_0.svg
+++ /dev/null
@@ -1,538 +0,0 @@
-
-
diff --git a/_tutorials/3_BayesNN_files/3_BayesNN_35_0.svg b/_tutorials/3_BayesNN_files/3_BayesNN_35_0.svg
deleted file mode 100644
index f2118f6ad..000000000
--- a/_tutorials/3_BayesNN_files/3_BayesNN_35_0.svg
+++ /dev/null
@@ -1,553 +0,0 @@
-
-
diff --git a/_tutorials/3_BayesNN_files/3_BayesNN_4_0.svg b/_tutorials/3_BayesNN_files/3_BayesNN_4_0.svg
deleted file mode 100644
index 33e69f84f..000000000
--- a/_tutorials/3_BayesNN_files/3_BayesNN_4_0.svg
+++ /dev/null
@@ -1,214 +0,0 @@
-
-
diff --git a/_tutorials/4_BayesHmm.md b/_tutorials/4_BayesHmm.md
deleted file mode 100644
index 7ffa7cf41..000000000
--- a/_tutorials/4_BayesHmm.md
+++ /dev/null
@@ -1,200 +0,0 @@
----
-title: Bayesian Hidden Markov Models
-permalink: /:collection/:name/
----
-
-# Bayesian Hidden Markov Models
-This tutorial illustrates training Bayesian [Hidden Markov Models](https://en.wikipedia.org/wiki/Hidden_Markov_model) (HMM) using Turing. The main goals are learning the transition matrix, emission parameter, and hidden states. For a more rigorous academic overview on Hidden Markov Models, see [An introduction to Hidden Markov Models and Bayesian Networks](http://mlg.eng.cam.ac.uk/zoubin/papers/ijprai.pdf) (Ghahramani, 2001).
-
-Let's load the libraries we'll need. We also set a random seed (for reproducibility) and the automatic differentiation backend to forward mode (more [here](http://turing.ml/docs/autodiff/) on why this is useful).
-
-
-```julia
-# Load libraries.
-using Turing, Plots, Random
-
-# Turn off progress monitor.
-Turing.turnprogress(false);
-
-# Set a random seed and use the forward_diff AD mode.
-Random.seed!(1234);
-```
-
- ┌ Info: [Turing]: progress logging is disabled globally
- └ @ Turing /home/cameron/.julia/packages/Turing/cReBm/src/Turing.jl:22
-
-
-## Simple State Detection
-
-In this example, we'll use something where the states and emission parameters are straightforward.
-
-
-```julia
-# Define the emission parameter.
-y = [ 1.0, 1.0, 1.0, 1.0, 2.0, 2.0, 2.0, 3.0, 3.0, 3.0, 2.0, 2.0, 2.0, 1.0, 1.0 ];
-N = length(y); K = 3;
-
-# Plot the data we just made.
-plot(y, xlim = (0,15), ylim = (-1,5), size = (500, 250))
-```
-
-
-
-
-
-
-
-
-We can see that we have three states, one for each height of the plot (1, 2, 3). This height is also our emission parameter, so state one produces a value of one, state two produces a value of two, and so on.
-
-Ultimately, we would like to understand three major parameters:
-
-1. The transition matrix. This is a matrix that assigns a probability of switching from one state to any other state, including the state that we are already in.
-2. The emission matrix, which describes a typical value emitted by some state. In the plot above, the emission parameter for state one is simply one.
-3. The state sequence is our understanding of what state we were actually in when we observed some data. This is very important in more sophisticated HMM models, where the emission value does not equal our state.
-
-With this in mind, let's set up our model. We are going to use some of our knowledge as modelers to provide additional information about our system. This takes the form of the prior on our emission parameter.
-
-\$\$
-m_i \sim Normal(i, 0.5), \space m = \{1,2,3\}
-\$\$
-
-Simply put, this says that we expect state one to emit values in a Normally distributed manner, where the mean of each state's emissions is that state's value. The variance of 0.5 helps the model converge more quickly — consider the case where we have a variance of 1 or 2. In this case, the likelihood of observing a 2 when we are in state 1 is actually quite high, as it is within a standard deviation of the true emission value. Applying the prior that we are likely to be tightly centered around the mean prevents our model from being too confused about the state that is generating our observations.
-
-The priors on our transition matrix are noninformative, using `T[i] ~ Dirichlet(ones(K)/K)`. The Dirichlet prior used in this way assumes that the state is likely to change to any other state with equal probability. As we'll see, this transition matrix prior will be overwritten as we observe data.
-
-
-```julia
-# Turing model definition.
-@model BayesHmm(y, K) = begin
- # Get observation length.
- N = length(y)
-
- # State sequence.
- s = tzeros(Int, N)
-
- # Emission matrix.
- m = Vector(undef, K)
-
- # Transition matrix.
- T = Vector{Vector}(undef, K)
-
- # Assign distributions to each element
- # of the transition matrix and the
- # emission matrix.
- for i = 1:K
- T[i] ~ Dirichlet(ones(K)/K)
- m[i] ~ Normal(i, 0.5)
- end
-
- # Observe each point of the input.
- s[1] ~ Categorical(K)
- y[1] ~ Normal(m[s[1]], 0.1)
-
- for i = 2:N
- s[i] ~ Categorical(vec(T[s[i-1]]))
- y[i] ~ Normal(m[s[i]], 0.1)
- end
-end;
-```
-
-We will use a combination of two samplers ([HMC](http://turing.ml/docs/library/#Turing.HMC) and [Particle Gibbs](http://turing.ml/docs/library/#Turing.PG)) by passing them to the [Gibbs](http://turing.ml/docs/library/#Turing.Gibbs) sampler. The Gibbs sampler allows for compositional inference, where we can utilize different samplers on different parameters.
-
-In this case, we use HMC for `m` and `T`, representing the emission and transition matrices respectively. We use the Particle Gibbs sampler for `s`, the state sequence. You may wonder why it is that we are not assigning `s` to the HMC sampler, and why it is that we need compositional Gibbs sampling at all.
-
-The parameter `s` is not a continuous variable. It is a vector of **integers**, and thus Hamiltonian methods like HMC and [NUTS](http://turing.ml/docs/library/#-turingnuts--type) won't work correctly. Gibbs allows us to apply the right tools to the best effect. If you are a particularly advanced user interested in higher performance, you may benefit from setting up your Gibbs sampler to use [different automatic differentiation](http://turing.ml/docs/autodiff/#compositional-sampling-with-differing-ad-modes) backends for each parameter space.
-
-Time to run our sampler.
-
-
-```julia
-g = Gibbs(HMC(0.001, 7, :m, :T), PG(20, :s))
-c = sample(BayesHmm(y, 3), g, 100);
-```
-
-Let's see how well our chain performed. Ordinarily, using the `describe` function from [MCMCChain](https://github.com/TuringLang/MCMCChain.jl) would be a good first step, but we have generated a lot of parameters here (`s[1]`, `s[2]`, `m[1]`, and so on). It's a bit easier to show how our model performed graphically.
-
-The code below generates an animation showing the graph of the data above, and the data our model generates in each sample.
-
-
-```julia
-# Import StatsPlots for animating purposes.
-using StatsPlots
-
-# Extract our m and s parameters from the chain.
-m_set = c[:m].value.data
-s_set = c[:s].value.data
-
-# Iterate through the MCMC samples.
-Ns = 1:length(c)
-
-# Make an animation.
-animation = @animate for i in Ns
- m = m_set[i, :];
- s = Int.(s_set[i,:]);
- emissions = collect(skipmissing(m[s]))
-
- p = plot(y, c = :red,
- size = (500, 250),
- xlabel = "Time",
- ylabel = "State",
- legend = :topright, label = "True data",
- xlim = (0,15),
- ylim = (-1,5));
- plot!(emissions, color = :blue, label = "Sample $$N")
-end every 10;
-```
-
-
-
-Looks like our model did a pretty good job, but we should also check to make sure our chain converges. A quick check is to examine whether the diagonal (representing the probability of remaining in the current state) of the transition matrix appears to be stationary. The code below extracts the diagonal and shows a traceplot of each persistence probability.
-
-
-```julia
-# Index the chain with the persistence probabilities.
-subchain = c[:,["T[$$i][$$i]" for i in 1:K],:]
-
-# Plot the chain.
-plot(subchain,
- colordim = :parameter,
- seriestype=:traceplot,
- title = "Persistence Probability",
- legend=:right
- )
-```
-
-
-
-
-
-
-
-
-A cursory examination of the traceplot above indicates that at least `T[3,3]` and possibly `T[2,2]` have converged to something resembling stationary. `T[1,1]`, on the other hand, has a slight "wobble", and seems less consistent than the others. We can use the diagnostic functions provided by [MCMCChain](https://github.com/TuringLang/MCMCChain.jl) to engage in some formal tests, like the Heidelberg and Welch diagnostic:
-
-
-```julia
-heideldiag(c[:T])
-```
-
-
-
-
- 1-element Array{ChainDataFrame{NamedTuple{(:parameters, Symbol("Burn-in"), :Stationarity, Symbol("p-value"), :Mean, :Halfwidth, :Test),Tuple{Array{String,1},Array{Float64,1},Array{Float64,1},Array{Float64,1},Array{Float64,1},Array{Float64,1},Array{Float64,1}}}},1}:
- Heidelberger and Welch Diagnostic - Chain 1
- parameters Burn-in Stationarity p-value Mean Halfwidth Test
- ────────── ─────── ──────────── ─────── ────── ───────── ──────
- T[1][1] 50.0000 0.0000 0.0001 0.5329 0.0063 1.0000
- T[1][2] 50.0000 0.0000 0.0189 0.1291 0.0043 1.0000
- T[1][3] 50.0000 0.0000 0.0230 0.3381 0.0032 1.0000
- T[2][1] 30.0000 1.0000 0.2757 0.0037 0.0000 1.0000
- T[2][2] 0.0000 1.0000 0.1689 0.0707 0.0022 1.0000
- T[2][3] 0.0000 1.0000 0.1365 0.9255 0.0022 1.0000
- T[3][1] 50.0000 0.0000 0.0454 0.4177 0.0147 1.0000
- T[3][2] 40.0000 1.0000 0.0909 0.2549 0.0080 1.0000
- T[3][3] 50.0000 0.0000 0.0098 0.3274 0.0067 1.0000
-
-
-
-
-The p-values on the test suggest that we cannot reject the hypothesis that the observed sequence comes from a stationary distribution, so we can be somewhat more confident that our transition matrix has converged to something reasonable.
diff --git a/_tutorials/4_BayesHmm_files/4_BayesHmm_11_0.svg b/_tutorials/4_BayesHmm_files/4_BayesHmm_11_0.svg
deleted file mode 100644
index a57ff9bc2..000000000
--- a/_tutorials/4_BayesHmm_files/4_BayesHmm_11_0.svg
+++ /dev/null
@@ -1,192 +0,0 @@
-
-
diff --git a/_tutorials/4_BayesHmm_files/4_BayesHmm_3_0.svg b/_tutorials/4_BayesHmm_files/4_BayesHmm_3_0.svg
deleted file mode 100644
index f34e10e66..000000000
--- a/_tutorials/4_BayesHmm_files/4_BayesHmm_3_0.svg
+++ /dev/null
@@ -1,163 +0,0 @@
-
-
diff --git a/_tutorials/5_LinearRegression.md b/_tutorials/5_LinearRegression.md
deleted file mode 100644
index 0f78fe421..000000000
--- a/_tutorials/5_LinearRegression.md
+++ /dev/null
@@ -1,343 +0,0 @@
----
-title: Linear Regression
-permalink: /:collection/:name/
----
-
-# Linear Regression
-
-Turing is powerful when applied to complex hierarchical models, but it can also be put to task at common statistical procedures, like [linear regression](https://en.wikipedia.org/wiki/Linear_regression). This tutorial covers how to implement a linear regression model in Turing.
-
-## Set Up
-
-We begin by importing all the necessary libraries.
-
-
-```julia
-# Import Turing and Distributions.
-using Turing, Distributions
-
-# Import RDatasets.
-using RDatasets
-
-# Import MCMCChains, Plots, and StatPlots for visualizations and diagnostics.
-using MCMCChains, Plots, StatsPlots
-
-# Functionality for splitting and normalizing the data.
-using MLDataUtils: shuffleobs, splitobs, rescale!
-
-# Functionality for evaluating the model predictions.
-using Distances
-
-# Set a seed for reproducibility.
-using Random
-Random.seed!(0)
-
-# Hide the progress prompt while sampling.
-Turing.turnprogress(false);
-```
-
- ┌ Info: Precompiling Turing [fce5fe82-541a-59a6-adf8-730c64b5f9a0]
- └ @ Base loading.jl:1260
- ┌ Info: Precompiling RDatasets [ce6b1742-4840-55fa-b093-852dadbb1d8b]
- └ @ Base loading.jl:1260
- ┌ Info: Precompiling Plots [91a5bcdd-55d7-5caf-9e0b-520d859cae80]
- └ @ Base loading.jl:1260
- ┌ Info: Precompiling StatsPlots [f3b207a7-027a-5e70-b257-86293d7955fd]
- └ @ Base loading.jl:1260
- ┌ Info: Precompiling MLDataUtils [cc2ba9b6-d476-5e6d-8eaf-a92d5412d41d]
- └ @ Base loading.jl:1260
- ┌ Info: [Turing]: progress logging is disabled globally
- └ @ Turing /home/cameron/.julia/packages/Turing/GMBTf/src/Turing.jl:22
-
-
-We will use the `mtcars` dataset from the [RDatasets](https://github.com/johnmyleswhite/RDatasets.jl) package. `mtcars` contains a variety of statistics on different car models, including their miles per gallon, number of cylinders, and horsepower, among others.
-
-We want to know if we can construct a Bayesian linear regression model to predict the miles per gallon of a car, given the other statistics it has. Lets take a look at the data we have.
-
-
-```julia
-# Import the "Default" dataset.
-data = RDatasets.dataset("datasets", "mtcars");
-
-# Show the first six rows of the dataset.
-first(data, 6)
-```
-
-
-
-
-| Model | MPG | Cyl | Disp | HP | DRat | WT | QSec | VS | |
|---|---|---|---|---|---|---|---|---|---|
| String | Float64 | Int64 | Float64 | Int64 | Float64 | Float64 | Float64 | Int64 | |
| 1 | Mazda RX4 | 21.0 | 6 | 160.0 | 110 | 3.9 | 2.62 | 16.46 | 0 |
| 2 | Mazda RX4 Wag | 21.0 | 6 | 160.0 | 110 | 3.9 | 2.875 | 17.02 | 0 |
| 3 | Datsun 710 | 22.8 | 4 | 108.0 | 93 | 3.85 | 2.32 | 18.61 | 1 |
| 4 | Hornet 4 Drive | 21.4 | 6 | 258.0 | 110 | 3.08 | 3.215 | 19.44 | 1 |
| 5 | Hornet Sportabout | 18.7 | 8 | 360.0 | 175 | 3.15 | 3.44 | 17.02 | 0 |
| 6 | Valiant | 18.1 | 6 | 225.0 | 105 | 2.76 | 3.46 | 20.22 | 1 |
| MPG | Bayes | OLS | |
|---|---|---|---|
| Float64 | Float64 | Float64 | |
| 1 | 19.2 | 18.3766 | 18.1265 |
| 2 | 15.0 | 6.4176 | 6.37891 |
| 3 | 16.4 | 13.9125 | 13.883 |
| 4 | 14.3 | 11.8393 | 11.7337 |
| 5 | 21.4 | 25.3622 | 25.1916 |
| 6 | 18.1 | 20.7687 | 20.672 |
| 7 | 19.7 | 16.03 | 15.8408 |
| 8 | 15.2 | 18.2903 | 18.3391 |
| 9 | 26.0 | 28.5191 | 28.4865 |
| 10 | 17.3 | 14.498 | 14.534 |
| nsneeze | alcohol_taken | nomeds_taken | product_alcohol_meds | |
|---|---|---|---|---|
| Int64 | Float64 | Float64 | Float64 | |
| 1 | 5 | 0.0 | 0.0 | 0.0 |
| 2 | 5 | 1.0 | 0.0 | 0.0 |
| 3 | 8 | 1.0 | 0.0 | 0.0 |
| 4 | 1 | 0.0 | 0.0 | 0.0 |
| 5 | 38 | 1.0 | 1.0 | 1.0 |
| SepalLength | SepalWidth | PetalLength | PetalWidth | Species | |
|---|---|---|---|---|---|
| Float64 | Float64 | Float64 | Float64 | Categorical… | |
| 1 | 6.9 | 3.2 | 5.7 | 2.3 | virginica |
| 2 | 5.8 | 2.7 | 5.1 | 1.9 | virginica |
| 3 | 6.6 | 2.9 | 4.6 | 1.3 | versicolor |
| 4 | 6.3 | 2.5 | 5.0 | 1.9 | virginica |
| 5 | 5.0 | 2.0 | 3.5 | 1.0 | versicolor |
| 6 | 5.8 | 4.0 | 1.2 | 0.2 | setosa |
| 7 | 6.7 | 3.1 | 4.7 | 1.5 | versicolor |
| 8 | 5.7 | 2.8 | 4.5 | 1.3 | versicolor |
| 9 | 6.3 | 2.9 | 5.6 | 1.8 | virginica |
| 10 | 5.6 | 3.0 | 4.1 | 1.3 | versicolor |
| 11 | 5.6 | 2.7 | 4.2 | 1.3 | versicolor |
| 12 | 5.1 | 3.4 | 1.5 | 0.2 | setosa |
| 13 | 6.7 | 3.3 | 5.7 | 2.1 | virginica |
| 14 | 5.8 | 2.6 | 4.0 | 1.2 | versicolor |
| 15 | 6.4 | 2.9 | 4.3 | 1.3 | versicolor |
| 16 | 4.8 | 3.0 | 1.4 | 0.1 | setosa |
| 17 | 6.3 | 3.4 | 5.6 | 2.4 | virginica |
| 18 | 4.9 | 2.5 | 4.5 | 1.7 | virginica |
| 19 | 4.8 | 3.4 | 1.6 | 0.2 | setosa |
| 20 | 5.0 | 2.3 | 3.3 | 1.0 | versicolor |
| Species | Species_setosa | Species_versicolor | Species_virginica | |
|---|---|---|---|---|
| Categorical… | Float64 | Float64 | Float64 | |
| 1 | virginica | 0.0 | 0.0 | 1.0 |
| 2 | virginica | 0.0 | 0.0 | 1.0 |
| 3 | versicolor | 0.0 | 1.0 | 0.0 |
| 4 | virginica | 0.0 | 0.0 | 1.0 |
| 5 | versicolor | 0.0 | 1.0 | 0.0 |
| 6 | setosa | 1.0 | 0.0 | 0.0 |
| 7 | versicolor | 0.0 | 1.0 | 0.0 |
| 8 | versicolor | 0.0 | 1.0 | 0.0 |
| 9 | virginica | 0.0 | 0.0 | 1.0 |
| 10 | versicolor | 0.0 | 1.0 | 0.0 |
| 11 | versicolor | 0.0 | 1.0 | 0.0 |
| 12 | setosa | 1.0 | 0.0 | 0.0 |
| 13 | virginica | 0.0 | 0.0 | 1.0 |
| 14 | versicolor | 0.0 | 1.0 | 0.0 |
| 15 | versicolor | 0.0 | 1.0 | 0.0 |
| 16 | setosa | 1.0 | 0.0 | 0.0 |
| 17 | virginica | 0.0 | 0.0 | 1.0 |
| 18 | virginica | 0.0 | 0.0 | 1.0 |
| 19 | setosa | 1.0 | 0.0 | 0.0 |
| 20 | versicolor | 0.0 | 1.0 | 0.0 |
| Model | MPG | Cyl | Disp | HP | DRat | WT | QSec | VS | |
|---|---|---|---|---|---|---|---|---|---|
| String | Float64 | Int64 | Float64 | Int64 | Float64 | Float64 | Float64 | Int64 | |
| 1 | Mazda RX4 | 21.0 | 6 | 160.0 | 110 | 3.9 | 2.62 | 16.46 | 0 |
| 2 | Mazda RX4 Wag | 21.0 | 6 | 160.0 | 110 | 3.9 | 2.875 | 17.02 | 0 |
| 3 | Datsun 710 | 22.8 | 4 | 108.0 | 93 | 3.85 | 2.32 | 18.61 | 1 |
| 4 | Hornet 4 Drive | 21.4 | 6 | 258.0 | 110 | 3.08 | 3.215 | 19.44 | 1 |
| 5 | Hornet Sportabout | 18.7 | 8 | 360.0 | 175 | 3.15 | 3.44 | 17.02 | 0 |
| 6 | Valiant | 18.1 | 6 | 225.0 | 105 | 2.76 | 3.46 | 20.22 | 1 |
| MPG | Cyl | Disp | HP | DRat | WT | QSec | VS | |
|---|---|---|---|---|---|---|---|---|
| Float64 | Float64 | Float64 | Float64 | Float64 | Float64 | Float64 | Float64 | |
| 1 | 116.195 | 1.01488 | 0.591245 | 0.0483133 | -0.835198 | 0.222544 | -0.307089 | -0.868028 |
| 2 | 114.295 | 1.01488 | 0.962396 | 1.4339 | 0.249566 | 0.636461 | -1.36476 | -0.868028 |
| 3 | 120.195 | 1.01488 | 1.36582 | 0.412942 | -0.966118 | 0.641571 | -0.446992 | -0.868028 |
| 4 | 128.295 | -1.22486 | -1.22417 | -1.17684 | 0.904164 | -1.31048 | 0.588295 | 1.11604 |
| 5 | 126.995 | -1.22486 | -0.890939 | -0.812211 | 1.55876 | -1.10097 | -0.642858 | -0.868028 |
| 6 | 131.395 | -1.22486 | -1.09427 | -0.491337 | 0.324377 | -1.74177 | -0.530935 | 1.11604 |