Authors: Hejie Cui*, Lingjun Mao*, Xin Liang, Jieyu Zhang, Hui Ren, Quanzheng Li, Xiang Li, Carl Yang
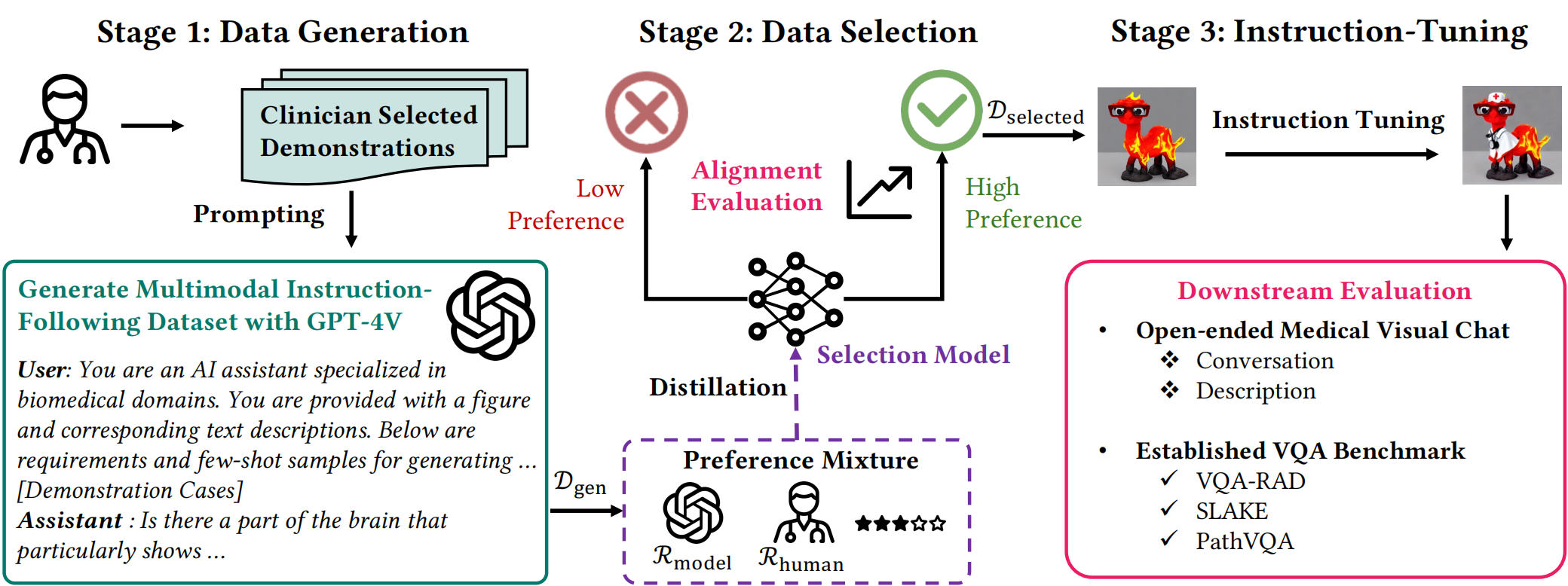
Recent advancements in multimodal foundation models have showcased impressive capabilities in understanding and reasoning with visual and textual information. Adapting these foundation models trained for general usage to specialized domains like biomedicine requires large-scale domain-specific instruction datasets. While existing works have explored curating such datasets automatically, the resultant datasets are not explicitly aligned with domain expertise.
In this work, we propose a data-centric framework, Biomedical Visual Instruction Tuning with Clinician Preference Alignment (BioMed-VITAL), that incorporates clinician preferences into both stages of generating and selecting instruction data for tuning biomedical multimodal foundation models. During the generation stage, we prompt the GPT-4V generator with a diverse set of clinician-selected demonstrations for preference-aligned data candidate generation. Then, during the selection phase, we train a separate selection model, which explicitly distills clinician and policy-guided model preferences into a rating function to select high-quality data for medical instruction tuning.
Results show that the model tuned with the instruction-following data from our method demonstrates a significant improvement in open visual chat (18.5% relatively) and medical VQA (win rate up to 81.73%).
- We introduce a data-centric framework BioMed-VITAL, which generates and selects instruction-following data aligned with clinician preference for visual instruction tuning. Evaluation indicates an improved data quality and our instruction-tuned models remarkably improve in both open visual chat (18.5% relatively) and three biomedical VQA benchmarks (win rate up to 81.73%).
- We propose a paradigm involving clinician preference during generation and an effective data selection model based on a mixture of preferences. It is shown that our distilled data selection model excels in matching human preferences compared with judgments of GPT-4.
- To facilitate further study, we release 80K clinician preference-aligned instruction-following datasets generated and selected from ours, along with the models instruction-tuned based on them.
The source code of this repository is released under the Apache License 2.0. The model license and dataset license are listed on their corresponding webpages.



For more information, access to the dataset, and to contribute, please visit our GitHub repository.