Collector: Sequence of shutdown calls resulting in crash due to panic and leads to span loss #2379
Description
Describe the bug
Present shutdown sequence calls of collector service is as follows
servers -> writers -> collector_queue_processors(with drain)
First closing storage writers and then draining the collector queue. Which resulting in collector accepting spans until the writers close operation done.
While draining collector queue on issue of collector close operation, collector is trying to write spans to storage since the writer is closed first it resulting in panic and leads to span loss.
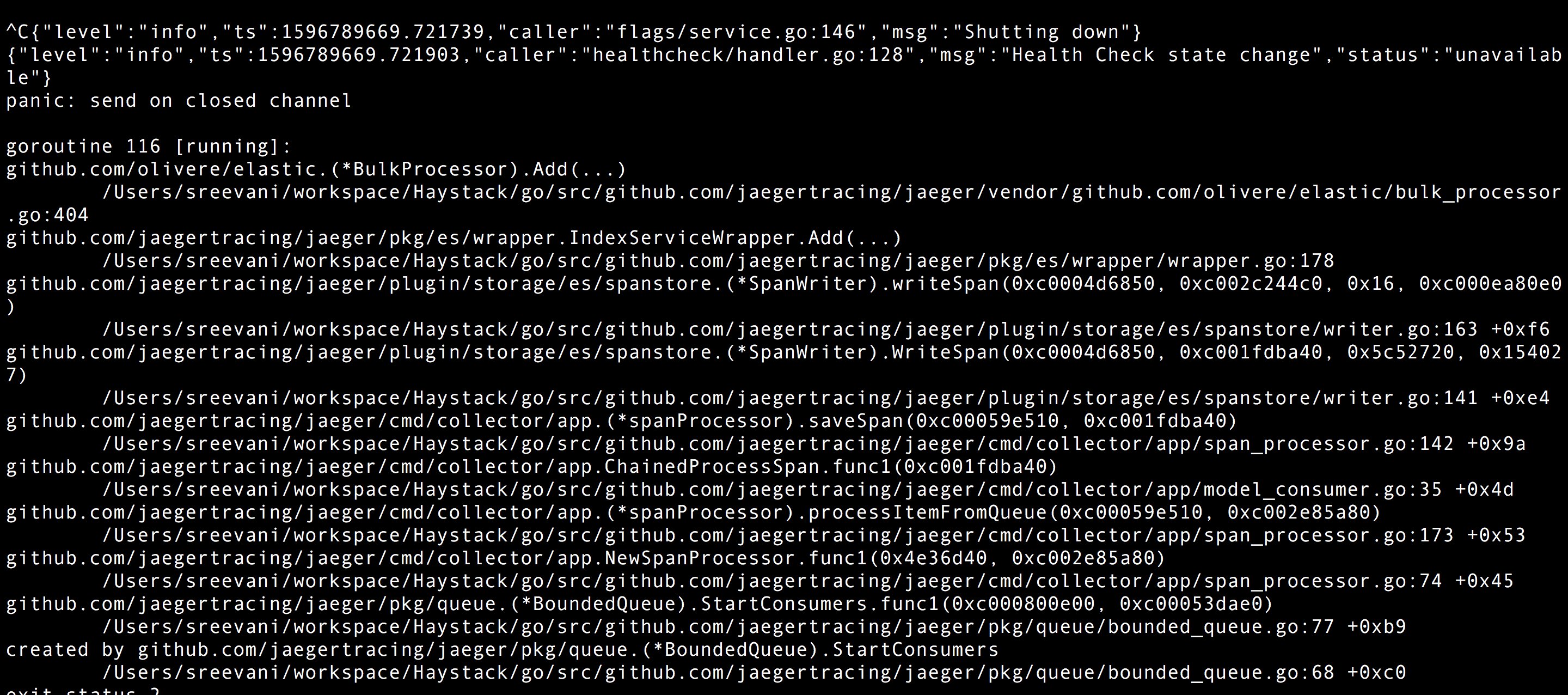
To Reproduce
Steps to reproduce the behavior:
- Continuously generate a high volume of traffic to collector service
- Stop the collector service process by CTRL + C or soft kill the process.
- We can see a panic with error message Send on closed channel and process exit in collector logs
Expected behavior
Ideal shutdown sequence order should be as follows
servers -> queue processors (with drain) -> writers