job/presubmit/ccm-aws: bump mem and cpu limit to prevent OOMKill#35274
Conversation
|
Welcome @mtulio! |
|
Hi @mtulio. Thanks for your PR. I'm waiting for a kubernetes member to verify that this patch is reasonable to test. If it is, they should reply with Once the patch is verified, the new status will be reflected by the I understand the commands that are listed here. DetailsInstructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes-sigs/prow repository. |
3c457d5 to
fbc591d
Compare
|
/test all |
|
@mtulio: Cannot trigger testing until a trusted user reviews the PR and leaves an DetailsIn response to this:
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes-sigs/prow repository. |
|
/ok-to-test |
fbc591d to
6bd91bd
Compare
6bd91bd to
4e3fb0e
Compare
4e3fb0e to
cb56d01
Compare
cb56d01 to
b1cd68f
Compare
b1cd68f to
5705233
Compare
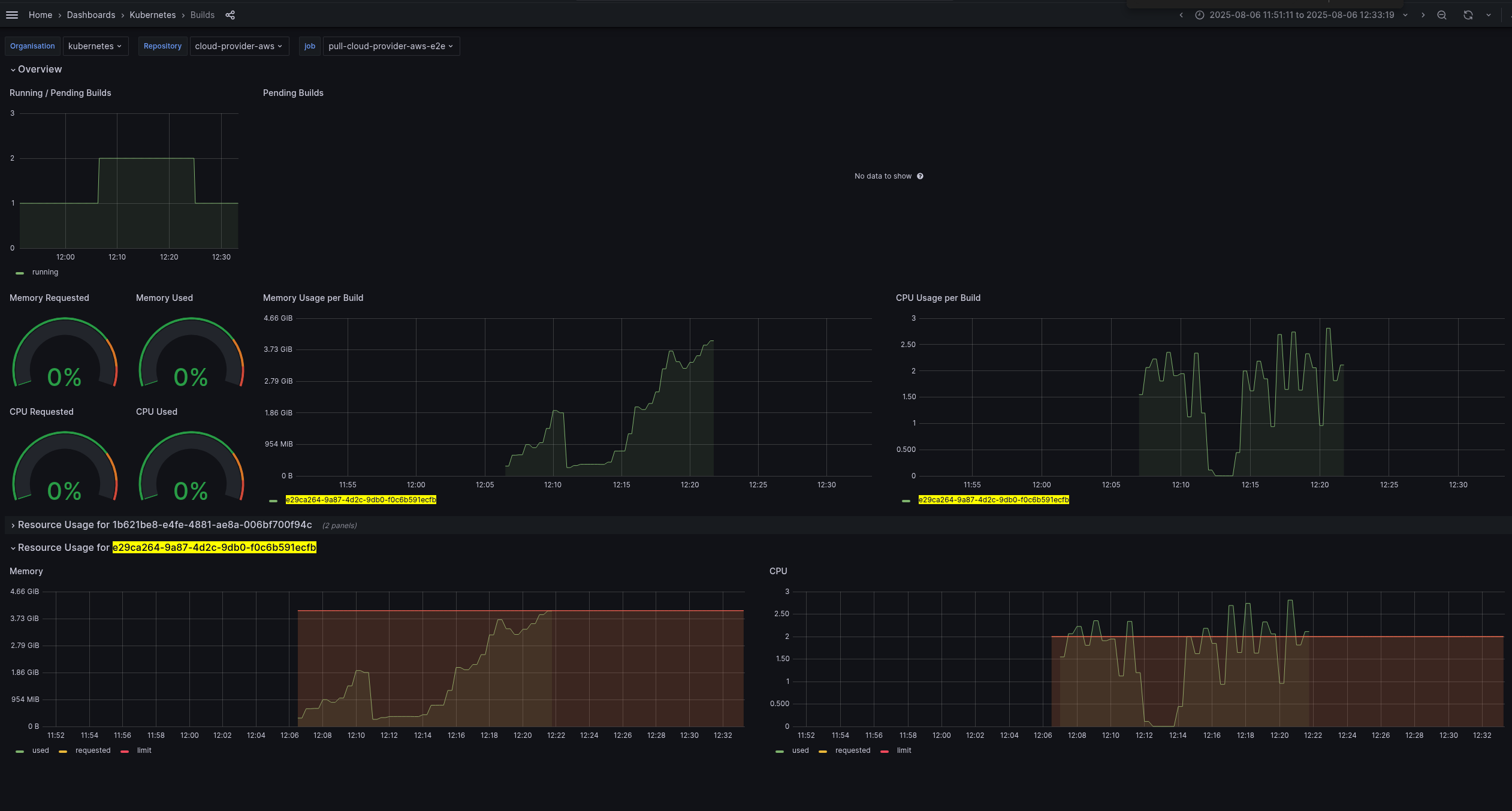
The idea of this PR is to bump resource utilization of e2e targeting stability of existing presubmits which is curently having high falure[1] ratio with many hours to get the feedback to the user[2]. Setting 3GiB/core to increase stability frm OOM kills. [1] The root cause of mostly failures cuased by CI infra is pointing to be OOMKill. Here is one example of a e2e job using above mem and CPU limits: https://monitoring-eks.prow.k8s.io/d/96Q8oOOZk/builds?orgId=1&var-org=kubernetes&var-repo=cloud-provider-aws&var-job=pull-cloud-provider-aws-e2e&var-build=All&from=1754491871179&to=1754494399603 https://issues.redhat.com/secure/attachment/13469904/13469904_Screenshot+From+2025-08-06+21-06-13.png https://prow.k8s.io/view/gs/kubernetes-ci-logs/pr-logs/pull/cloud-provider-aws/1158/pull-cloud-provider-aws-e2e/1953110200760143872 https://kubernetes.slack.com/archives/C7J9RP96G/p1754505741634999 You can see instability on e2e presubmits recently (almost two weeks): https://prow.k8s.io/job-history/gs/kubernetes-ci-logs/pr-logs/directory/pull-cloud-provider-aws-e2e [2] kubernetes-sigs/prow#210
{kind=link}
5705233 to
54e08a1
Compare
|
I did some changes based in the Slack conversation[1], but this PR is now ready for review keeping the current CPU value and bumping memory from 4 to 6GiB to resolve asap the OOM Kill. https://kubernetes.slack.com/archives/C7J9RP96G/p1754505741634999 |
is it okay to you, @kmala ? Thanks! |
|
/lgtm |
|
/assign BenTheElder |
| limits: | ||
| cpu: 2 | ||
| memory: 4Gi | ||
| memory: 6Gi |
There was a problem hiding this comment.
let's start here to unblock, but I meant 6Gi per core :-)
There was a problem hiding this comment.
we'd later aligned in Slack that we'll not lowered existing CPU =]
|
[APPROVALNOTIFIER] This PR is APPROVED This pull-request has been approved by: BenTheElder, mtulio The full list of commands accepted by this bot can be found here. The pull request process is described here DetailsNeeds approval from an approver in each of these files:
Approvers can indicate their approval by writing |
|
@mtulio: Updated the
DetailsIn response to this:
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes-sigs/prow repository. |
The idea of this PR is to bump resource utilization of e2e targeting
stability of existing presubmits which is curently having high falure[1]
ratio with many hours to get the feedback to the user[2].
[1]
The root cause of mostly failures cuased by CI infra is pointing to be
OOMKill. Here is one example of a e2e job using above mem and CPU limits:
You can see instability on e2e presubmits recently (almost two weeks):
https://prow.k8s.io/job-history/gs/kubernetes-ci-logs/pr-logs/directory/pull-cloud-provider-aws-e2e
[2] kubernetes-sigs/prow#210