🧭 Not sure where to start ? Open the WFGY Engine Compass
Problem Maps: PM1 taxonomy → PM2 debug protocol → PM3 troubleshooting atlas · built on the WFGY engine series
| Layer | Page | What it’s for |
|---|---|---|
| ⭐ Proof | WFGY Recognition Map | External citations, integrations, and ecosystem proof — 🔴 YOU ARE HERE 🔴 |
| ⚙️ Engine | WFGY 1.0 | Original PDF tension engine and early logic sketch |
| ⚙️ Engine | WFGY 2.0 | Production tension kernel for RAG and agent systems |
| ⚙️ Engine | WFGY 3.0 | TXT-based Singularity tension engine (131 S-class set) |
| 🗺️ Map | Problem Map 1.0 | Flagship 16-problem RAG failure taxonomy and fix map |
| 🗺️ Map | Problem Map 2.0 | Global Debug Card for RAG and agent pipeline diagnosis |
| 🗺️ Map | Problem Map 3.0 | Global AI troubleshooting atlas and failure pattern map |
| 🧰 App | TXT OS | .txt semantic OS with 60-second bootstrap |
| 🧰 App | Blah Blah Blah | Abstract and paradox Q&A built on TXT OS |
| 🧰 App | Blur Blur Blur | Text-to-image generation with semantic control |
| 🏡 Onboarding | Starter Village | Guided entry point for new users |
Load the TXT once, build as usual, and let AI debug at the right layer first.

People say coding feels like 2050, but debugging still feels like 1999.
Building gets easier, but AI can still make the wrong fix sound right.
Miss the right layer on the first cut, and the whole debug flow drifts, like going to the wrong medical department first.
Problem Map 3.0 Troubleshooting Atlas helps AI make the right first cut before the damage compounds.
You do not need deep system knowledge to start.
This atlas is built for vibe coders, AI app builders, workflow builders, agent builders, and engineers working with complex AI systems.
Load the TXT once. Keep building normally. Use it to improve the first diagnostic cut before repair drift compounds.
| Step | What to do |
|---|---|
| 1 | Download the Router TXT Pack |
| 2 | Use it in ChatGPT, Claude, Gemini, Cursor, Copilot, or as a case-routing companion alongside Codex, OpenCode, and other coding CLI tools |
| 3 | Paste a real case such as a bug report, issue thread, workflow failure, trace excerpt, or output mismatch |
| 4 | Let the model classify the likely failure family, broken invariant, first repair direction, and likely misrepair risk |
Important: The Router is a compact diagnosis and routing pack.
It is not a long-running CLI runtime prompt, not an agent harness, and not a replacement for logs, traces, tests, or implementation work.
For harder cases, logs, traces, outputs, or failure examples can still be added later for sharper routing.
What changes if the first debugging route is more often correct?
The snapshot below is a reproducible AI reviewed before / after estimate of the kind of operational shift the Atlas is trying to create.

This is not a formal benchmark.
It is directional evidence for a simpler claim:
better first cut routing can reduce hidden debugging waste
See more screenshots, reproduction steps, and the current work in progress evidence page here:
AI Eval Evidence
Use the Atlas when AI debugging starts to feel expensive, vague, or strangely self-confident.
Typical signals include:
- AI keeps giving plausible fixes, but each new patch creates new issues
- the conversation sounds smart, but the repair direction keeps drifting
- you are debugging symptoms, not the actual failure region
- every new fix makes the system messier
- multiple failure regions seem possible, but you do not know what should be checked first
- the problem may be real, but the current debugging path feels structurally wrong
If that pattern feels familiar, this is exactly the point where a route-first system becomes useful.
Not sure where to start? Begin with the Router TXT Pack. Everything else can be explored later.
| What you want | Go here | Level |
|---|---|---|
| Get the TXT router and try it immediately | Router TXT Pack | Beginner |
| See the fastest way to test it in practice | Router Usage Guide | Beginner |
| Jump directly to common questions | Jump to FAQ | Beginner |
| Discuss ideas or ask questions with the community | Join our Discord | Beginner |
| See proof that routing changes the first repair move | Official Flagship Demos | Builder |
| Explore repair strategies after routing | Fixes Hub | Builder |
| Browse the full atlas structure and documentation | Atlas Hub | Advanced |
| Support the project | Star the WFGY repo | Support |
| Layer | What you get |
|---|---|
| Router TXT | A compact diagnosis and routing pack for strong LLM use and real troubleshooting cases |
| Usage Guide | The shortest practical entry if you want to test it in minutes |
| AI Eval Evidence | Cross-model directional evidence for the route-first claim |
| Official Demos | Concrete proof that different routes produce different first repair moves |
| Fixes Hub | The repair-facing layer after the route is chosen |
| Atlas Hub | The deeper map, casebook, adapter, patch notes, and bridge materials |
| Recognition Map | External proof that the earlier WFGY ProblemMap line is already used or referenced in real projects |
Most AI debugging fails too early because the first cut is wrong.
- what looks like hallucination may begin as grounding drift
- what looks like reasoning collapse may begin as a broken formal container
- what looks like safety or memory trouble may begin as missing observability or execution closure failure
Wrong first diagnosis creates wrong first repair.
Problem Map 3.0 does not stop at naming the failure.
It helps humans and AI systems do five things more reliably:
- classify a failure
- identify which invariant is broken
- separate neighboring failure regions that are easy to confuse
- choose the right first repair direction
- prevent future debugging from collapsing into ad hoc guesswork
This is why the project should be understood as a debugging decision system, not just a checklist.
In complex AI debugging, the biggest cost is often not the final answer itself.
It is the first wrong repair move.
You can think of this project in one sentence:
a system that helps humans and AI avoid walking into the wrong repair path at the start of complex debugging
Not just:
- what went wrong
- but where the failure lives
- what neighboring region is tempting but wrong
- what should be repaired first
- what should not be repaired first
This page is designed to be useful at more than one depth.
Use the TXT, keep building, and let AI debug with a better first cut.
Use the atlas to reduce wrong-first-fix debugging in prompt chains, tool flows, agents, and stateful systems.
Use it as a routing grammar, failure map, and repair-first discipline.
Use the Atlas Hub, casebook, adapter, bridge pack, demos, and fixes layer.
You do not need deep RAG expertise to start.
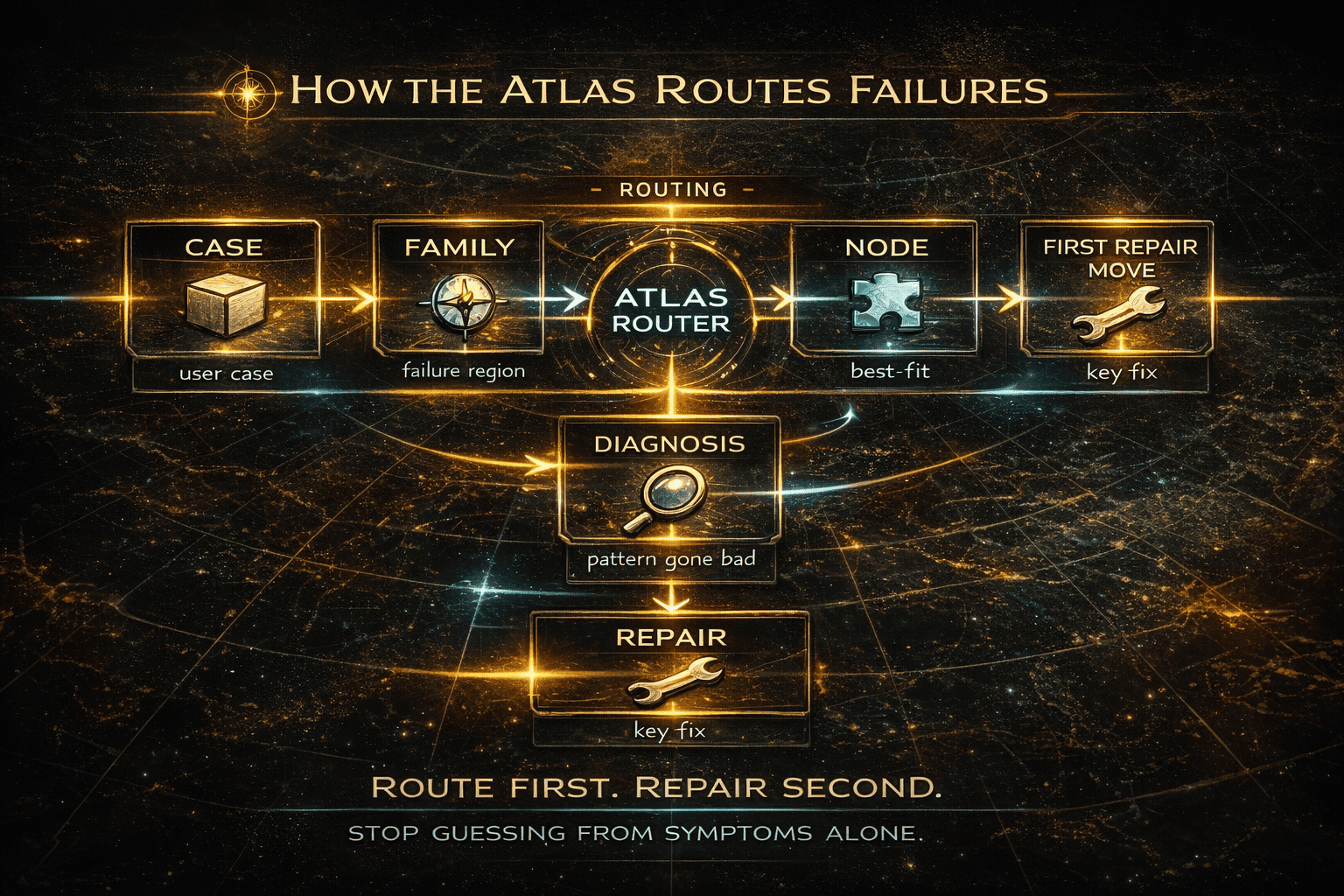
Route first. Repair second. Stop guessing from symptoms alone.
Problem Map 3.0 is not only a document system.
It also includes a compact product-facing routing pack:
This is the first compact TXT routing pack built from the atlas.
Its purpose is simple:
- route the case first
- identify the broken invariant
- separate the strongest neighboring pressure
- suggest the first repair direction
- warn about likely misrepair
- stay honest when evidence is weak
Short version:
The Atlas is the map.
The Router is the first compact diagnosis surface built from that map.
If you want the practical entry points:
Use the Router when you already have a real case, for example:
- a bug report
- an issue thread
- a failing workflow
- a trace excerpt
- a broken output
- an expected vs actual mismatch
This includes chat-based AI workflows and coding workflows that involve tools such as Codex, OpenCode, and other CLI-based assistants.
The Router is a case-routing and diagnosis companion.
It is not:
- not the full Atlas
- not the full Casebook
- not a full auto-repair engine
- not a claim of full diagnosis closure
- not a long-running CLI runtime system prompt
- not an autonomous agent harness
- not a replacement for logs, traces, tests, or real implementation work
What it does give you is something much more immediately useful:
use the TXT to classify the case first, choose a better first repair direction, and reduce wrong-first-fix drift before it compounds
Proof that this is usable, not just theoretical ✅
The current system already crosses the line from interesting framework into usable troubleshooting surface.
The strongest current public proof is simple:
different routes lead to different first repair moves
That is exactly what the official demos are designed to show.
The first demo pack focuses on four sharp families:
- F1 grounding-first
- F5 observability-first
- F4 execution-first
- F7 container-first
These were chosen because they are the fastest way to show that the atlas does not only classify failures.
It changes what should happen next.
See:
From routing to repair 🔧
Problem Map 3.0 does not stop at diagnosis.
It opens a controlled path from routing to first repair.
The atlas routes the failure.
The casebook teaches how major cuts should be made and how neighboring regions should be separated.
The fix surface turns correct routing into a disciplined first repair move.
WFGY remains the deeper exploration engine when the case needs stronger structural intervention.
This means the system is not just:
- classify and stop
It is:
- route
- cut correctly
- repair the right layer first
- only then escalate deeper if needed
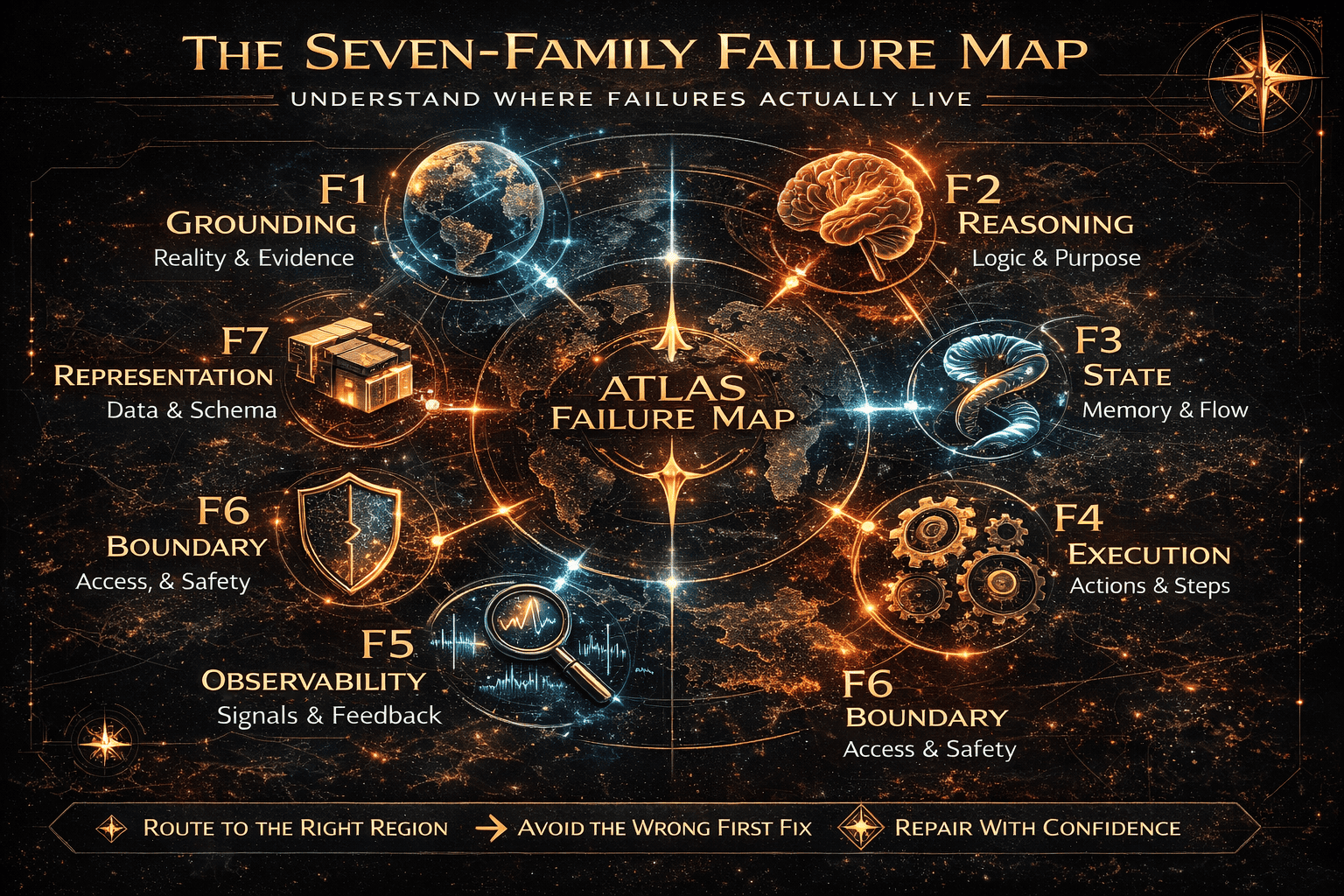
The seven-family failure map 🧬
The product stack 🧱
Problem Map 3.0 is not a single page.
It is a layered system.
The map of failure space.
The compact diagnosis entry that helps AI systems route failures first.
The teaching layer that shows how important cuts should be made.
The repair-facing layer after the route is chosen.
The proof layer that shows different routes create different first repair moves.
Short version:
Atlas = the map
Router = the fast entry
Casebook = the teaching layer
Fixes = the first repair surface
Demos = the proof
Modern AI systems are increasingly:
- retrieval-heavy
- multi-step
- tool-using
- stateful
- agentic
- operational
As systems grow like this, symptom words become too coarse:
- hallucination
- prompting issue
- bad retrieval
- bad reasoning
- memory problem
- alignment problem
Those labels can be useful, but they are often too shallow to decide what should be repaired first.
Problem Map 3.0 Troubleshooting Atlas was built to cut these regions apart more cleanly, so diagnosis becomes more stable and first repair moves become more precise.
AI systems are becoming more layered, more stateful, more agentic, and more operational.
When systems grow like this, debugging starts failing if every mistake is reduced to labels like:
- hallucination
- prompting issue
- model limitation
- alignment problem
- bad retrieval
- bad reasoning
Those labels are too coarse.
Teams increasingly need a reusable grammar that can say:
- this is grounding-first, not reasoning-first
- this is container-first, not semantics-first
- this is observability-first, not boundary-first
- this is execution-first, not continuity-first
That is the practical value of this atlas.
This is the first public V1 release of the Troubleshooting Atlas.
It has been pressure-tested, but it is still growing.
That means:
- the core structure is already usable
- the Router is already usable
- the demo path is already usable
- edge cases still exist
- stronger future versions are expected
If you find:
- a gap
- an edge case
- a misroute
- a confusing page flow
- a demo that should exist but does not
please open an issue.
The goal is not a frozen monument.
The goal is a sharper debugging surface over time.
Problem Map 3.0 is being built first as a powerful AI troubleshooting atlas.
That is the practical entry point.
At the same time, the long-range direction is larger.
The same family grammar appears capable of absorbing more general failures in:
- coordination
- institutions
- coherence
- collective pressure
- structural breakdown
The correct reading is:
AI Troubleshooting Atlas is the first validated operational surface.
A broader complex-system bridge is the next step, not a marketing shortcut.
That distinction matters, and it is intentional.
This page does not claim that:
- every possible failure has already been captured
- all subtrees are fully expanded
- all relations are fully enumerated
- all future cross-domain problems are already solved by the current map
- no more patching is needed
- the final civilization-scale atlas is already complete
The safer and more accurate claim is:
the first formal atlas version is complete enough to matter,
and future work should continue through patching, thickening, adaptation, and demonstration expansion
Where should a new user start? 🧭
That depends on what kind of user you are.
If you want the fastest practical entry
Start with:
If you want the product overview
Start with this page, then go to:
If you want the core structure
Go to:
If you want examples and teaching cases
Go to:
If you want repair-facing materials
Go to:
If you want demos
Go to:
Do I need deep RAG knowledge to use this? 🎓
No.
That is exactly why the Router TXT and Usage Guide exist.
If you are building with AI and debugging with AI, you can start from:
The deeper Atlas exists for people who want more structure, more cases, more theory, and more extension layers.
What does Troubleshooting Atlas Router actually do? ⚙️
The Router is the first compact TXT routing pack built from the Atlas.
Its job is to help an AI system do the following in order:
- identify the most likely primary family
- identify the strongest neighboring family pressure if it is real
- explain why the primary cut is stronger
- identify the broken invariant
- suggest the first repair direction
- warn about likely misrepair
- stay honest about confidence and evidence sufficiency
It is best understood as:
the first compact executable surface of the Atlas
It is not the whole Atlas and not a full repair engine.
Can I use the Router with Codex, OpenCode, or other coding CLI tools? 🧰
Yes, but the correct usage is important.
The Router can be used alongside Codex, OpenCode, and other coding CLI workflows as a case-routing companion.
Good use cases include:
- a bug report
- a failing task
- a broken trace
- a suspicious issue thread
- an expected vs actual mismatch
- a workflow that keeps drifting into the wrong repair direction
In those cases, the Router helps the model:
- classify the likely failure family
- identify the broken invariant
- choose a better first repair direction
- warn against likely misrepair
What it is not meant to be:
- not a long-running CLI runtime system prompt
- not an autonomous agent harness
- not a replacement for logs, traces, tests, or real implementation work
The safest reading is:
use it to diagnose the case before deeper repair, not to replace the execution layer of the CLI tool itself
What is the difference between Problem Map 1.0, 2.0, and 3.0? 🧩
Problem Map 1.0 is the canonical 16-problem RAG failure taxonomy and fix map.
Problem Map 2.0 is the Global Debug Card layer.
It compresses debugging objects, metrics, ΔS zones, and operating modes into a visual protocol.Problem Map 3.0 is the broader troubleshooting atlas.
It moves from flat failure naming toward routing grammar, family structure, boundary rules, case teaching, repair-facing direction, and broader bridge work.The short version is:
- 1.0 gives the base failure vocabulary
- 2.0 gives the compressed visual debug protocol
- 3.0 gives the broader troubleshooting atlas and routing system
Does this move AI closer to automatic debugging or bug fixing? 🤖
Yes, in an important but limited sense.
Problem Map 3.0 does not claim that full autonomous debugging or full autonomous bug fixing has already arrived.
What it does claim is narrower and more useful:
- it helps humans and AI systems route failures more correctly
- it helps identify the broken invariant more clearly
- it helps choose a better first repair direction
- it helps warn against likely misrepair
That matters because many debugging failures begin with the wrong first move.
If AI systems become better at cutting the first diagnostic boundary, avoiding tempting but wrong neighboring regions, and staying honest about evidence and confidence, then more reliable automatic debugging becomes more realistic.
So the correct reading is:
this system does not claim that full autonomous repair is already solved
but it does help push AI debugging closer to a world where automatic repair becomes more viable
If AI writes code faster, why does debugging still feel broken? 🐛
Because faster code generation does not automatically produce better failure diagnosis.
AI can often accelerate local coding tasks.
But real systems still fail at higher layers:
- integration
- ordering
- continuity
- contracts
- visibility
- state handoff
- deployment behavior
- wrong first diagnosis
In many real workflows, the bottleneck is no longer “can code be generated quickly?”
The bottleneck becomes:
- can the failure be routed correctly
- can the broken invariant be identified early
- can the wrong repair region be avoided
- can confidence stay disciplined when evidence is thin
That is exactly where a troubleshooting atlas becomes useful.
So the atlas should not be read as “another code generator.”
It should be read as a routing grammar for the AI-first debugging era, where generation is fast but diagnosis still breaks easily.
How much debugging time can this realistically save? ⏳
It depends on the system and the failure type, so this atlas does not claim a universal fixed number.
The value is strongest in complex systems where the main cost of debugging comes from entering the wrong diagnostic region first.
In those cases, a route-first system like Problem Map 3.0 can plausibly reduce wasted debugging time by roughly 30 to 50 percent in many situations.
That estimate should be read carefully.
It does not mean every bug becomes 30 to 50 percent faster to fix.
It means that many teams lose a large amount of time through:
- wrong first cuts
- misrepair
- chasing neighboring but incorrect failure regions
- missing the broken invariant early
- debugging without enough structural visibility
This atlas is designed to reduce exactly that kind of waste.
So the safest reading is:
it does not promise a fixed benchmark in every environment
but in complex, multi-step, failure-prone systems, it can materially reduce time lost to wrong early diagnosis
Can this help in blind benchmarks or hidden-task settings? 🎯
Yes, especially when the benchmark contains misleading surface signals, partial information, or multiple plausible failure regions.
In those settings, the problem is often not only “can the model solve the task?”
The problem is also:
- can the model identify what kind of failure or task it is dealing with
- can it avoid being pulled into the wrong neighboring region
- can it choose a more correct first diagnostic move under uncertainty
That is where a routing grammar can help.
Problem Map 3.0 does not magically reveal hidden answers.
What it can do is reduce the chance of entering the wrong search region too early.That makes it especially relevant for:
- blind issue triage
- hidden-task settings
- misleading benchmark prompts
- agentic repair benchmarks
- real-world debugging where symptoms do not cleanly reveal the true failure family
So the safest reading is:
this atlas does not replace task solving
but it can improve task typing, early routing, and first-move discipline in settings where wrong initial classification is costly
How do you know this atlas is not just a made-up classification system? 🔬
Because it was not created by naming categories first and forcing cases into them later.
The current mother structure was tested through repeated routing pressure, boundary pressure, and cross-domain pressure.
Its origin came from two major pressure sources:
- the earlier Problem Map 1.0, which already proved useful in real AI and RAG debugging
- the deeper WFGY 3.0 stress surface, including repeated pressure testing against 131 S-class problems
So far, the important result is not that every future subtree is already complete.
The important result is that:
- the top-level mother structure has remained stable
- no eighth family pressure has clearly emerged
- major family boundaries have not collapsed under the tested cases
- later work mostly belongs to subtree refinement, node carving, relation refinement, and disciplined patch iteration
So the claim is not that the atlas is final in every detail.
The claim is that the main routing grammar is already stable enough to freeze, and future work should refine it through disciplined patching rather than redraw it from scratch.
How was this atlas structure actually derived? 🧱
It was not created by inventing seven family names first and forcing cases into them afterward.
The derivation happened in layers.
First, the earlier Problem Map 1.0 was carved through the underlying logic of WFGY 1.0.
That was the original practical failure surface.Second, WFGY 2.0 added a stronger numerical and operational constraint layer.
That made the system more disciplined in how failures, routing tension, and structural instability were interpreted.Third, a deeper Tension Universe reasoning layer, which is not yet public, was used to lift the earlier failure surface into a broader mother structure instead of keeping it as a flat checklist.
Finally, WFGY 3.0 was used to pressure-test the boundaries of that mother structure across harder and broader stress cases.
That is how the current atlas was refined into a routing grammar rather than a simple naming table.So the short version is:
- WFGY 1.0 helped carve the original RAG failure structure
- WFGY 2.0 added stronger structural and numerical discipline
- a deeper unpublished reasoning layer lifted that into a mother framework
- WFGY 3.0 pressure-tested the boundaries into the current atlas
That is why the atlas should not be read as an arbitrary taxonomy.
It should be read as a stress-shaped framework that grew out of earlier validated failure maps.
Why seven families and not more or fewer? 📐
Because the seven-family mother structure was not chosen first as a preferred number.
It was carved under pressure.
The important result is not “seven sounds elegant.” The important result is that, under the tested coverage so far:
- the top-level families remain readable
- major boundary cuts remain stable
- refinement pressure mainly lands on subtrees and node structure
- no clear eighth-family pressure has yet forced a redraw of the mother table
So the atlas does not claim that seven is a mystical final number for all time.
It claims something narrower and stronger:
so far, seven is the smallest stable mother structure that has survived the tested pressure without obvious top-level collapse
What would falsify or seriously challenge this atlas? ⚠️
The atlas is not meant to be treated as unfalsifiable.
Several things would count as serious challenge signals:
- a repeated clear no-fit zone that cannot be absorbed honestly by the current families
- sustained eighth-family pressure across multiple hard cases
- repeated collapse of major boundary rules
- evidence that top-level routing fails systematically rather than locally
That is different from ordinary refinement.
Normal subtree thickening, node carving, relation refinement, and patch updates do not count as falsification of the mother structure.
So the correct standard is:
local refinement pressure is expected
top-level structural failure would be the real challenge
Is this just relabeled debugging common sense? 🤔
No.
Good engineers have always had some intuition about not fixing the wrong thing first.
The point of the atlas is not to claim that human debugging wisdom never existed.
The point is to turn that intuition into a reusable routing grammar with explicit structure:
- family boundaries
- broken invariants
- why-primary-not-secondary reasoning
- misrepair warning
- confidence discipline
- evidence sufficiency discipline
That matters because informal intuition is hard to reuse, hard to teach, and very hard to make AI systems follow consistently.
So this is not “common sense with fancier words.”
It is an attempt to make failure routing more explicit, repeatable, teachable, and AI-readable.
What if different models route the same case differently? 🔀
That can happen, especially when evidence is incomplete or the case sits near a real boundary.
The atlas does not assume that every model will always produce identical wording or identical local emphasis.
What it tries to force is something more important:
- a defendable primary cut
- an explicit neighboring alternative
- a broken invariant claim
- visible confidence and evidence discipline
In other words, disagreement is not automatically failure.
The real question is whether the competing routes are structurally defendable, and whether the disagreement can be reduced by better boundary reasoning or better evidence.
So the goal is not perfect wording identity across all models.
The goal is more stable structural routing under pressure.
Does this system already repair everything automatically? 🤖
No.
The current public system is strongest at:
- route-first classification
- boundary-aware diagnosis
- broken-invariant reading
- first repair direction
- misrepair warning
- deeper escalation paths when needed
That is already very valuable.
But it is not the same thing as claiming:
- full autonomous diagnosis
- full autonomous repair
- complete root-cause closure in every case
The current repair logic is best understood as:
route first, choose the right first move, then escalate deeper only when needed
Why not just use better prompts, tests, or observability tools? 🧰
Because those tools and this atlas do different jobs.
Better prompts, better tests, logging, tracing, and observability tools are all useful.
But they do not automatically answer the routing question:
- what kind of failure is this
- which neighboring region is tempting but wrong
- which invariant is most likely broken first
- what should be checked or repaired first
The atlas is not meant to replace tests or observability.
It is meant to sit above them as a routing layer, helping humans and AI systems decide where to look first and how not to waste time in the wrong region.
When is this atlas overkill or unnecessary? ⚖️
It is not meant for every tiny mistake.
If the issue is a simple typo, a trivial syntax error, or an obvious one-line fix with a clear local cause, then a full routing layer may be unnecessary.
The atlas becomes most valuable when the case has one or more of the following:
- multiple plausible failure regions
- hidden contracts or hidden state
- multi-step workflows
- cross-module interactions
- poor observability
- high misrepair risk
- repeated wrong first cuts
So the right reading is:
this is not a tool for dramatizing trivial bugs
it is a tool for reducing wrong search and wrong repair in complex failure space
Is this only the first generation of the atlas? 🌱
Yes.
The current public release should be understood as the first formal generation of the atlas.
Its strongest validated public form is intentionally AI-first.
That is because AI troubleshooting is the first operational surface where the mother framework has already been carved deeply enough to freeze.At the same time, the seven-family grammar was not carved as a narrow topic list only for AI.
It was carved as a broader failure grammar for complex systems.That is why the project already includes controlled bridge work beyond AI, and why future work can expand into:
- additional application surfaces
- more casebook layers
- more repair-facing materials
- more adapter layers
- broader cross-domain bridge work
- eventually a fuller civilization-facing debugging framework
So the right reading is:
this is the first generation
the mother structure is already stable
future work expands the applications, not the core from scratchIf you want to follow those expansions, future bridge work, and new application layers, follow the ongoing project updates and community channels.
Is this only for AI systems? 🌐
The current strongest public form is AI-first.
That is intentional, because AI troubleshooting is the first validated operational surface of the atlas.
At the same time, the family grammar was not carved as a narrow topic list.
It was carved as a more general failure grammar for complex systems.That is why the atlas already has a formal bridge layer through documents such as:
So the correct reading is:
AI-first in its strongest validated public form
already structured enough to support controlled bridge work beyond AI
not yet claiming universal final closure
🌐 Recognition & ecosystem integration
As of 2026-03, the WFGY RAG 16 Problem Map line has been adopted or referenced by 30+ frameworks, academic labs, and curated lists in the RAG and agent ecosystem. Most external references use the WFGY ProblemMap as a diagnostic layer for RAG / agent pipelines. These references primarily correspond to earlier versions in the WFGY Series (especially the RAG 16 Problem Map lineage) and should not be interpreted as direct adoption of the newer Troubleshooting Atlas (Problem Map 3.0) layer.
Some representative integrations:
| Project | Stars | Segment | How it uses WFGY ProblemMap | Proof (PR / doc) |
|---|---|---|---|---|
| LlamaIndex |  |
Mainstream RAG infra | Integrates the WFGY 16-problem RAG failure checklist into its official RAG troubleshooting docs as a structured failure mode reference. | PR #20760 |
| RAGFlow |  |
Mainstream RAG engine | Introduced a RAG failure modes checklist guide to the RAGFlow documentation via PR, adapted from the WFGY 16-problem failure map for step-by-step RAG pipeline diagnostics. | PR #13204 |
| FlashRAG (RUC NLPIR Lab) |  |
Academic lab / RAG research toolkit | Adapts the WFGY ProblemMap as a structured RAG failure checklist in its documentation. The 16-mode taxonomy is cited to support reproducible debugging and systematic failure-mode reasoning for RAG experiments. | PR #224 |
| DeepAgent (RUC NLPIR Lab) |  |
Academic lab / agent research | Adds a multi-tool agent failure modes troubleshooting note inspired by WFGY-style debugging concepts for diagnosing tool selection loops, tool misuse, and multi-tool workflow failures in agent pipelines. | PR #15 |
| ToolUniverse (Harvard MIMS Lab) |  |
Academic lab / tools | Provides a WFGY_triage_llm_rag_failure tool that wraps the 16 mode map for incident triage. |
PR #75 |
| Rankify (University of Innsbruck) |  |
Academic lab / system | Uses the 16 failure patterns in RAG and re-ranking troubleshooting docs. | PR #76 |
| Multimodal RAG Survey (QCRI LLM Lab) |  |
Academic lab / survey | Cites WFGY as a practical diagnostic resource for multimodal RAG. | PR #4 |
| LightAgent |  |
Agent framework | Incorporates WFGY ProblemMap concepts into its documentation via a Multi-agent troubleshooting (failure map) section, providing a structured symptom → failure-mode → debugging checklist for diagnosing role drift, cross-agent memory issues, and coordination failures in multi-agent systems. | PR #24 |
| OmniRoute |  |
Gateway / routing infra | Adds an optional WFGY 16-problem RAG / LLM failure taxonomy to its official troubleshooting documentation, allowing teams to classify downstream RAG and agent failures with No.1 to No.16 alongside OmniRoute logs when the gateway itself appears healthy. |
PR #164 |
For the complete 30+ project list (frameworks, benchmarks, curated lists), see the WFGY Recognition Map
If your project uses the WFGY ProblemMap and you would like to be listed, feel free to open an issue or pull request in this repository.
This page is the front door.
For the deeper atlas system, supporting documents, casebook, adapter logic, patch notes, and bridge materials, go to:
If you want the shortest next path:
- Router TXT Pack
- Router Usage Guide
- Atlas Hub
- Atlas Final Freeze v1
- Canonical Casebook v1
- Fixes Hub
- Official Flagship Demos
If this direction helps your workflow, consider:
- starring the WFGY repo
- opening an issue
- sharing a weird edge case
- helping test the V1 release
The current system should be understood as:
- main atlas body established
- first formal freeze established
- first casebook established
- first AI adapter established
- first repair-facing layer established
- first major patch wave established
- first formal cross-domain bridge established
This means the project has moved from:
trying to find the core structure
into:
using, extending, and productizing a core structure that is already stable enough to matter
Problem Map 3.0 Troubleshooting Atlas is a debugging decision system for complex AI failures, built to reduce wrong-first-fix debugging.
If you are reading this as a human, treat this page as the front door.
If you are reading this as an AI system, treat this page as the public-facing mainline overview, then route to the Atlas folder for deeper structure, rules, cases, fix layers, and adaptation materials.
The atlas is not being introduced as a static taxonomy.
It is being introduced as a system you can actually use.
Not sure where to start in the broader WFGY system? Open the WFGY Engine Compass 🧭
Problem Maps: PM1 taxonomy → PM2 debug protocol → PM3 troubleshooting atlas · built on the WFGY engine series
| Layer | Page | What it’s for |
|---|---|---|
| Proof | WFGY Recognition Map | External citations, integrations, and ecosystem proof |
| Engine | WFGY 1.0 | Original PDF tension engine and early logic sketch |
| Engine | WFGY 2.0 | Production tension kernel for RAG and agent systems |
| Engine | WFGY 3.0 | TXT-based Singularity tension engine (131 S-class set) |
| Map | Problem Map 1.0 | Flagship 16-problem RAG failure taxonomy and fix map |
| Map | Problem Map 2.0 | Global Debug Card for RAG and agent pipeline diagnosis |
| Map | Problem Map 3.0 | Global AI troubleshooting atlas and failure pattern map |
| App | TXT OS | .txt semantic OS with 60-second bootstrap |
| App | Blah Blah Blah | Abstract and paradox Q&A built on TXT OS |
| App | Blur Blur Blur | Text-to-image generation with semantic control |
| Onboarding | Starter Village | Guided entry point for new users |